并行程序设计与算法笔记
此份笔记是本人学习过程中自己总结记录的,其内容受到课堂教学内容、采用教材、个人认知水平的影响。虽然笔者力图保证内容准确以及易于理解(起码自己能看懂),但难免存在谬误或者渲染问题。非常欢迎您通过邮件等方式联系我修改,让我们一起让这份笔记变得更好!
第一章 为什么需要并行?
随着技术的发展,我们的计算能力越来越强,但是我们需要计算的问题的规模也越来越大。例如气候模型、蛋白质折叠、药物筛选、大数据分析等。
这些年来,处理器的能力不断提升,包括:
- 位宽从 4 bit 提升到 64 bit
- 流水线更高效,从 3.5 CPI (Cycles Per Instruction)提升到 1.1 CPI
- 指令级并行(ILP)的提升,包括超标量(Superscalar)、乱序执行(Out-of-Order Execution)等
- 更高的时钟频率,从 10 MHz 提升到数个 GHz
迄今为止,我们计算能力的提升主要依赖于晶体管密度的增加,其会受到固有的物理极限的限制。越小的晶体管意味着同一面积下可以放置更多的晶体管,也就意味着更快的处理器。但是,功耗和发热也会随之增加,导致处理器的稳定性和寿命受到影响。对于单核系统而言,晶体管数量的增加已经无法让时钟频率以及 ILP 继续按指数规则提升。
所以,目前的主流处理器设计方向转为多核系统。
编写一个并行程序包括任务并行化(Task Parallelism)和数据并行化(Data Parallelism)两种方式。任务并行化是指将一个大任务分解为多个小任务,每个小任务可以独立执行。数据并行化是指将一个大数据集分解为多个小数据集,每个小数据集可以独立处理。
以助教帮忙改卷为例,任务并行化就是每个助教改若干份试卷;数据并行化就是每个助教只负责改所有试卷的某几道题。
核之间需要相互协调(Coordiation),目的是为了进行必要的数据交换,负载均衡以及同步进度。
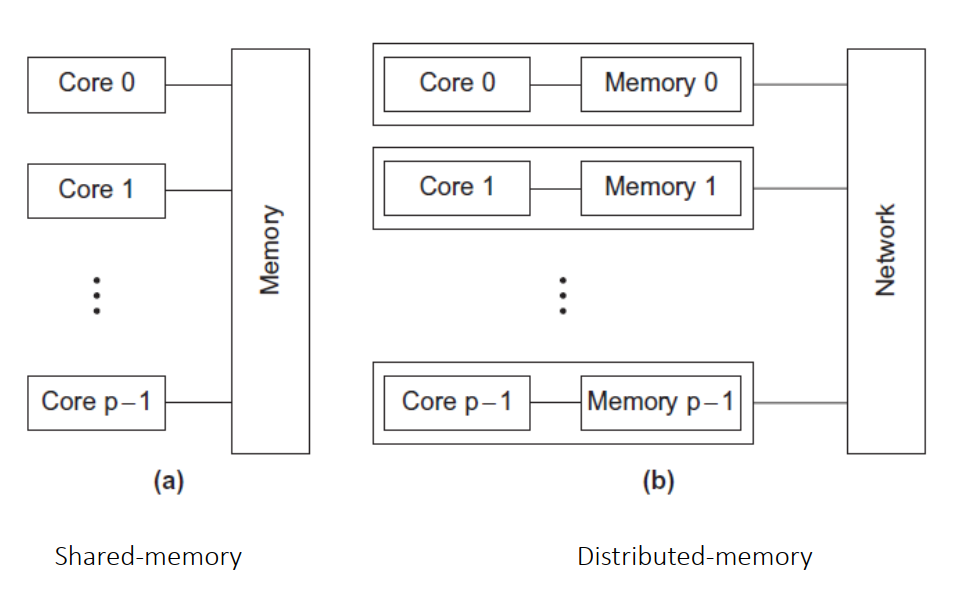
并行系统(Parallel System)有两种类型:
- 共享内存(Shared Memory):多个核共享同一块内存,核之间通过读写共享内存来进行通信。
- 分布式内存(Distributed Memory):每个核有自己的内存,核之间通过网络显式地发送信息来进行通信。
一些术语:
- 并发(Concurrency)计算:同一时间段内,能够处理多个任务(时间片轮转),这些任务不一定要在同一个实例(时间片)上执行。
- 并行(Parallelism)计算:强调能够同时处理多个任务(executing simultaneously),执行发生在同一个实例上(例如多核处理器)。并行计算在单核处理器上是不可能实现的。
- 分布式计算:强调多个计算机之间的协作。
举例说明的话,并发计算就像人们排成两个队伍,等待同一个窗口的服务;并行计算就像两个窗口同时服务两个队伍。
第二讲 并行硬件和并行软件
1、对冯诺依曼架构的改进
传统冯诺依曼架构如下图所示:
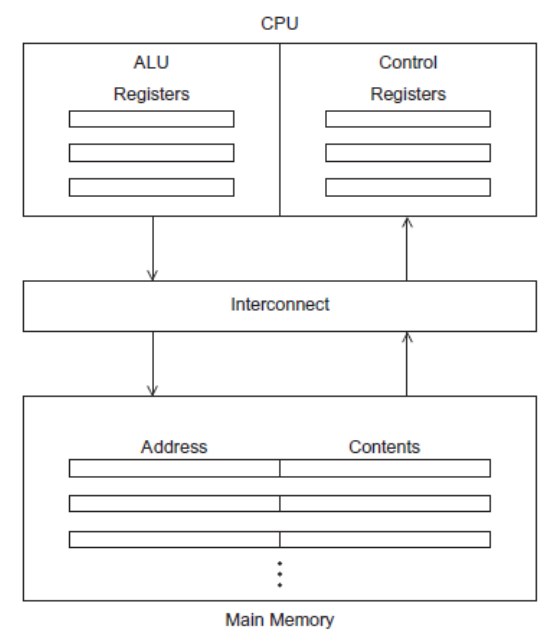
其主要瓶颈是 CPU 与内存之间速度不匹配,CPU 的速度远远快于内存的速度。
为了解决这个问题,我们引入了缓存(Cache)。CPU Cache 通常和 CPU 集成在一起,其访问速度比主存要快得多。引入缓存主要是利用了空间局部性(Spatial Locality)和时间局部性(Temporal Locality)。CPU 需要数据时,首先尝试从 Cache 中读取,如果 Cache 中没有,再从主存中读取。如果主存中也没有,再从磁盘中读取。写同理。
引入缓存之后,缓存中的内容可能与主存中的内容不一致,这就引入了一致性(Consistency)问题。通常有两种解决方案:
- 写直达(Write Through):写入 Cache 的同时写入主存
- 写回(Write Back):只写入 Cache,利用脏位(Dirty Bit)标记 Cache 中的数据是否被修改,当 Cache 中的数据被替换时,且要被其他数据替换时,将修改后的数据写回主存
另一个技术是虚拟内存(Virtual Memory),包括与之相关的页表、TLB 等技术,此处不再赘述。
2、指令级并行
指令级并行通过合理安排多个处理器部件或(Functional Unit),使得多条指令可以同时执行。
在计算机组成原理课程中提到的流水线技术(Pipeline)就是一种指令级并行的技术。流水线技术将指令执行过程分为多个阶段,每个阶段由不同的功能单元执行,不同指令的不同阶段可以并行执行。
另一种技术是多发射技术(Multiple Issue)。CPU 中同一种类型的功能单元有多个,所以可以同时执行多条指令。
多发射分为:
- 静态多发射(Static Multiple Issue):编译器在编译时决定指令的执行顺序
- 动态多发射(Dynamic Multiple Issue):CPU 在运行时决定指令的执行顺序。动态多发射也称之为超标量(Superscalar)
3、硬件多线程
硬件多线程技术使得某个线程在等待某些资源时,可以切换到另一个线程执行,从而提高 CPU 的利用率。
硬件多线程技术有多种:
- 细粒度多线程(Fine-Grained Multithreading):一个线程执行了一条指令后,就切换到另一个线程执行,跳过被阻塞的线程。其优点是避免了阻塞的线程浪费 CPU 时间,缺点是对于包含大量指令的线程,需要花费更久的时间才能完成。
- 粗粒度多线程(Coarse-Grained Multithreading):只有阻塞线程是在等待需要花费较久时间的操作时,才会切换到另一个线程执行。其优点是避免了频繁的线程切换,缺点是阻塞线程浪费一定的 CPU 时间。
- 同步多线程(Simultaneous Multithreading,SMT):允许多个线程可以同时使用 CPU 不同的功能单元。
下图展示了不同多线程技术之间的区别。其中每一条代表一个 CPU 周期,一条中的四个小方格代表 CPU 的四个功能单元。小方格涂上颜色表示该功能单元正在执行某个线程的指令。不同颜色代表不同的线程:
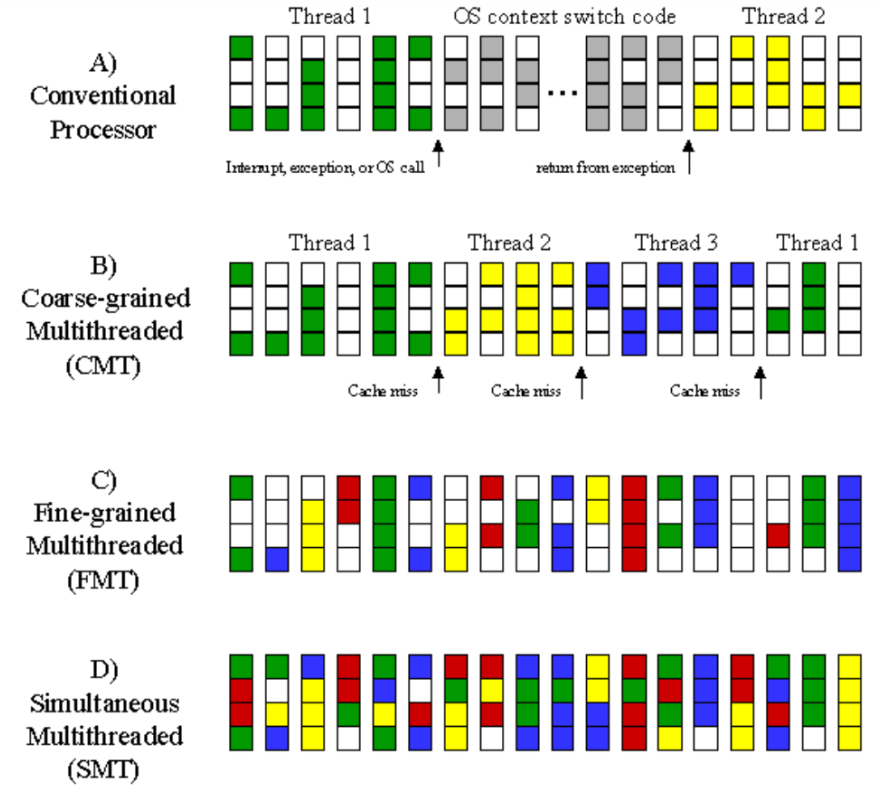
由图可见,SMT 可以很大程度地利用 CPU 的功能单元,提高 CPU 的利用率。
4、程序、进程和线程
程序(Program)是存储在计算机上的为了完成某项任务的代码。
一个程序可以有多个正在运行的实例,这些实例称之为进程(Process)。每个进程拥有独立的内存地址空间,不同的进程之间相互隔离,只能访问自己的内存地址空间。
线程(Thread)可以理解为进程中的执行单元。每个线程有独立的栈,但是共享堆。
5、CPU、核心和处理器
核心(Core)是 CPU 的基本计算单元,一个核心可以支持一个程序上下文(Program Context)运行。如果核心支持硬件线程(Hardware Thread),或者说虚拟 CPU 核心,例如 Intel CPU 的超线程技术,那么一个核心可以支持多个程序上下文。
超线程(Hyper-Threading)技术是 Intel 公司推出的一种多线程技术,其可以让一个物理 CPU 核心模拟出两个逻辑 CPU 核心,从而可以同时执行两个线程。两个逻辑核心共享物理核心的执行资源,例如 ALU、缓存、总线等。
处理器(Processor)是一个通用的术语,可以描述一组 CPU。多核处理器系统就可以包含多个 CPU。
6、并行计算机的分类
传统计算机分类方法中:
- 根据尺寸,可以分为微型机、小型机、中型机、大型机等
- 根据类型,可以分为模拟计算机、数字计算机、混合计算机等
- 根据用途,可以分为专用计算机和通用计算机等
传统的计算机分类方法有一定的局限性,上面的分类方法不能反映出机器的系统结构特征。随着计算机硬件技术的发展,划分标准也需要不断变化。
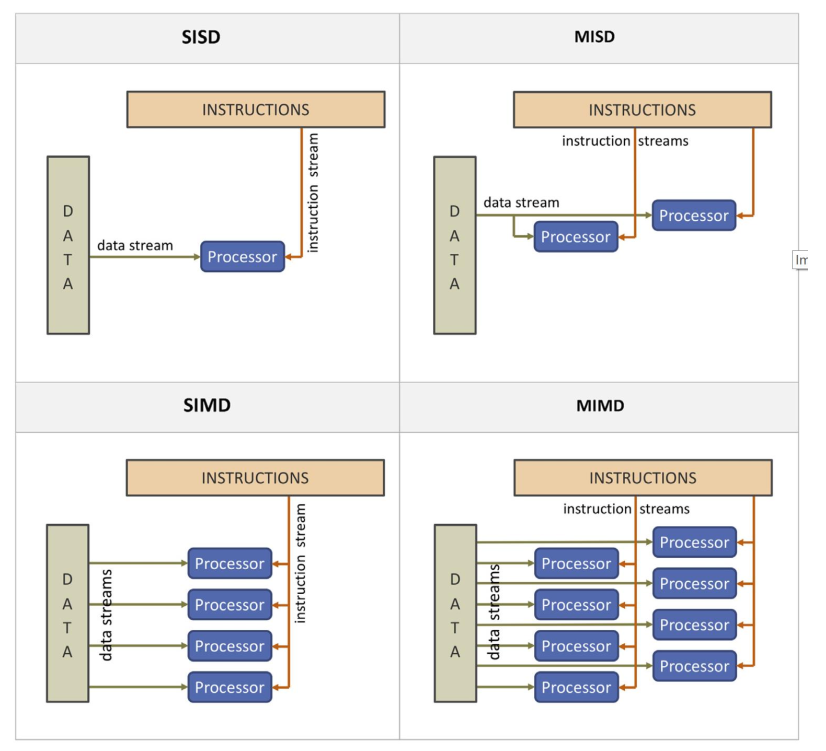
6.1、弗林分类法
弗林(Michael J. Flynn)提出了一种基于数据流和指令流的并行性关系的分类方法,称之为弗林分类法(Flynn’s Taxonomy)。
其将计算机系统分为四类:
- SISD(Single Instruction Single Data):单指令流单数据流,例如传统冯诺伊曼计算机
- SIMD(Single Instruction Multiple Data):单指令流多数据流,例如向量计算机和阵列计算机
- MISD(Multiple Instruction Single Data):多指令流单数据流,理论上存在,但是实际中很少见
- MIMD(Multiple Instruction Multiple Data):多指令流多数据流,例如多核处理器系统
其中指令流指的是机器之心的指令序列,数据流指的是指令流调用的数据系列。多倍性(Multiple),指的是在系统性能瓶颈部件上处于同一执行阶段的指令或数据的最大可能个数。以 SIMD 为例,其上一条指令可以同时操作多个数据。
向量计算机属于 SIMD 体系结构的一种,其是专门处理向量的计算机。向量计算机以向量为基本操作单元,操作数和结果都以向量的形式存在,主要以流水线结构为主。
向量计算机中的向量处理器呢个够对数组和数据向量进行操作,其包括或支持:
- 向量存储器
- 可以进行向量化操作的功能部件,也即能够对向量中的每个元素执行相同的的操作
- 步长式存储访问,能够访问向量中固定间隔的元素
- 硬件散射/聚集,也即对无固定间隔的数据进行读和写
SIMT(Single Instruction Multiple Threads),单指令流多线程流,是一种并行计算中使用的模型,将 SIMD 和多线程结合在一起,广泛应用于 GPU 上的计算单元中。可以理解为,其通过多线程来模拟 SIMD 的效果。
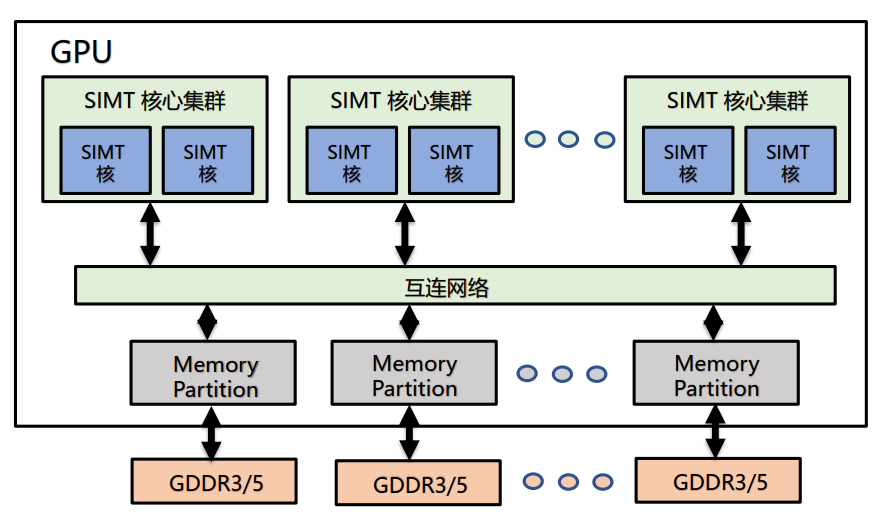
SIMT 相比 SIMD:
- SIMT 更加灵活。SIMT 允许一条指令中的多数据分开寻址,SIMD 则必须是连续在一起的片段。SIMT 中每个线程可以独立处理不同数据,适合不规则数据的并行处理。
- SIMT 中的每个线程的寄存器都是私有的,线程之间只能通过共享内存和同步机制进行通信。而 SIMD 中的向量中元素之间可以自由通信,SIMD 的向量存在于相同的地址空间。
GPU(Graphics Processing Unit)是一种专门用于处理图形数据的处理器,其最初是为了处理图形数据而设计的,但是随着计算需求的增加,GPU 也开始用于一般的并行计算。
在处理图形数据时,对邻近的元素会使用相同的着色函数,相当于对多个数据使用同一条指令,所以说 GPU 使用 SIMD 并行来优化性能。但是 GPU 不是纯粹的 SIMD 系统,是在一个给定的核的 ALU 使用了 SIMD 并行。GPU 实际有很多个核,每个核都能独立执行指令流。
GPU 严重依赖硬件多线程,需要避免内存访问的延迟。
6.2、MIMD 的细化分类
弗林分类法分类的对象主要是控制驱动方式下的串行和并行处理计算机,对于非控制驱动方式的计算机则不适合。同时其还存在分类过粗的问题。
对弗林分类法的拓展如下:
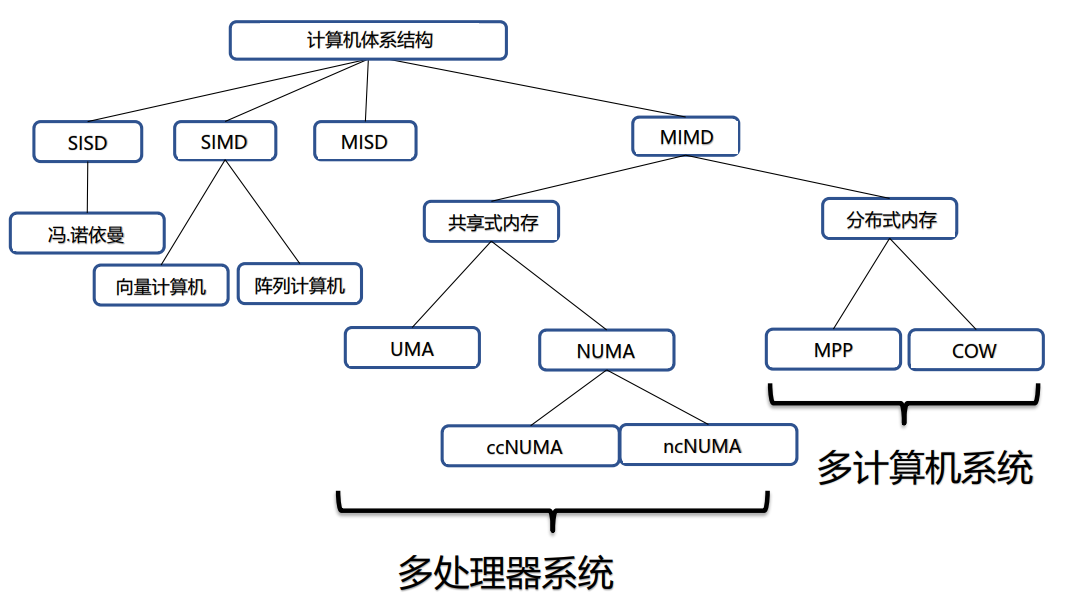
根据不同的 CPU 之间是如何组织和共享内存的,MIMD 机器可以分为共享式内存和分布式内存
6.2.1、共享式内存
共享式内存(Shared Memory)是指多个 CPU 共享同一块内存,CPU 之间通过读写共享内存来进行通信。
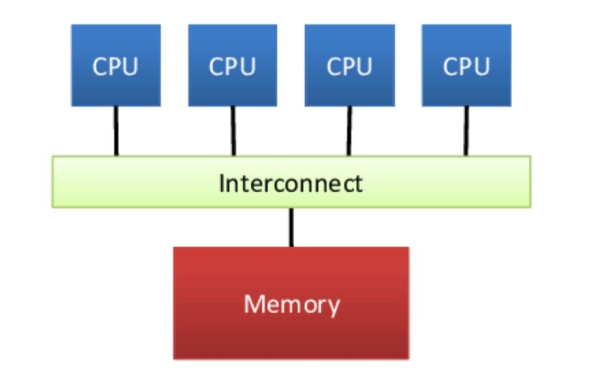
其进一步又可以分为:
- 集中式共享内存系统/对称多处理器系统/一致存储访问系统
- 分布式共享内存系统/非一致存储访问系统
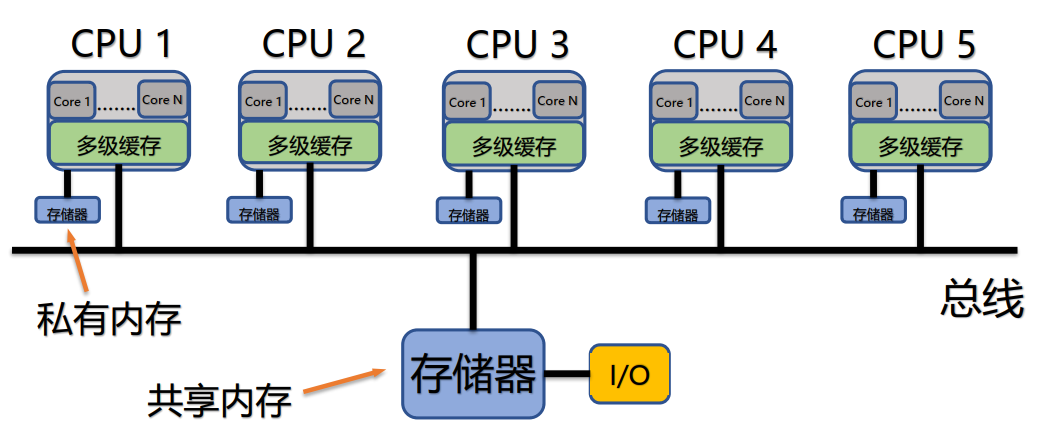
集中式共享内存系统(Centralized Shared Memory System)中处理器数目少,所有处理器共享一个集中式的存储器。
所有的处理器能够平等地访问存储器,所以该系统也称为对称多处理器系统(Symmetric Multiprocessor System);访问存储其的延迟自然也是相同的,所以该系统也称为一致存储访问系统(Uniform Memory Access System,UMA)。
每个处理器还可以拥有私有内存或高速缓存:
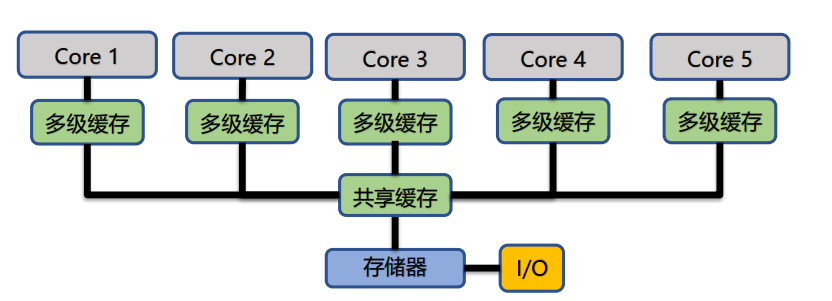
分布式共享内存系统(Distributed Shared Memory System)中每个处理器都拥有自己的存储器,也可以访问其他节点的存储器。
访问其他节点存储器(远程内存)的延迟比访问本地存储器(本地内存)的延迟要高,所以该系统也称为非一致存储访问系统(Non-Uniform Memory Access System,NUMA)。
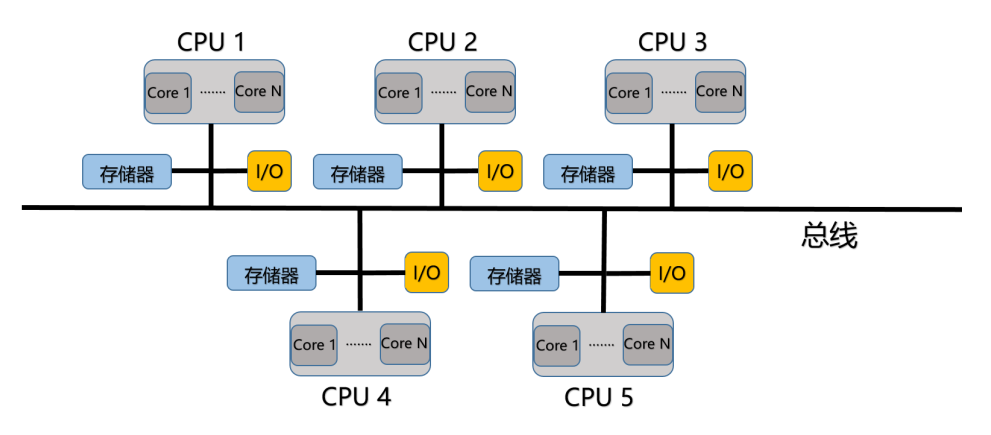
目前几乎所有的多核心多处理器系统都使用了分布式存储器。下面是不带缓存的分布式共享内存系统(NC-NUMA):
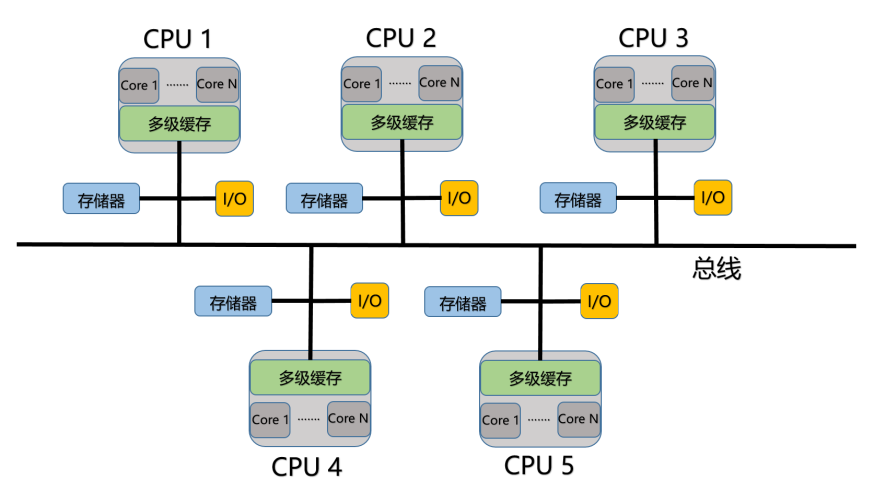
以及带缓存的分布式共享内存系统,(CC-NUMA):
6.2.2、分布式内存
分布式内存(Distributed Memory)是指处理器之间不共享内存。对于需要共享的数据,必须作为一个消息从一个处理器传递到另一个处理器。所以基于分布式内存的 MIMD 计算机也称为基于消息驱动的计算机。
每台计算机都有自己的处理器,每个处理器都有自己的私有内存,私有内存只能被自己的处理器访问,其他的计算机的处理器不能直接访问。每个计算机都有自己独立的物理地址空间。
其可以分为两类:大规模并行处理机系统和工作站集群系统
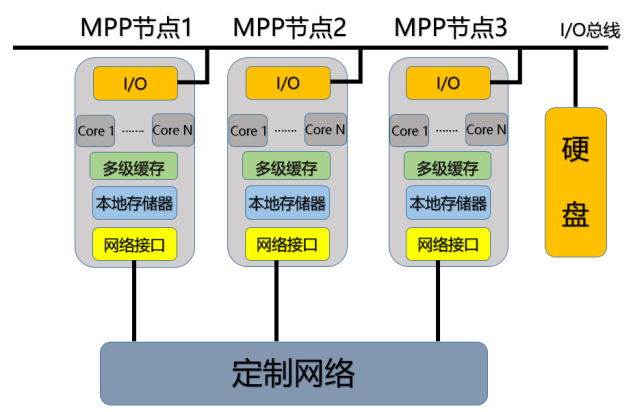
大规模并行处理机系统(Massively Parallel Processing System,MPP)中,每个节点可以认为是一个没有硬盘的计算机,由一条 I/O 总线连接到同一个硬盘上。
MPP 节点是高度集成的,通常没有独立的操作系统,依赖于全局调度和管理系统。
MPP 使用的网络一般是制造商专有的定制高速通信网络,延迟低、带宽高,适合大规模并行计算。
工作站集群系统(Cluster Of Workstations,COW),也称为仓库级计算机(Worstations Cluster),是由大量的家用计算机或者工作站通过商用网络(例如以太网,延迟较高,带宽较低,适合松散耦合任务)连接在一起而构成的多计算机系统,例如大型互联网公司的数据中心。
COW 中的每个节点可以认为是独立的计算机,有自己的硬盘、处理器、存储器等,各自允许操作系统和应用程序。
7、非冯诺依曼体系结构
冯诺伊曼体系结构的特点包括:
- 单处理机结构,机器以运算器为中心
- 指令和数据无差别的存储在存储器内
- 指令由操作码和操作数组成,都是顺序执行的
- 数据以二进制形式表示
- 软件和硬件完全分离
首先,其本质上就是串行的工作机制,而且指令与数据在同一个存储器,高速运行时,不能同时取指令和取操作时,形成瓶颈。
非冯诺依曼结构针对冯诺依曼结构的缺点,提出了一些改进:
- 采用多个处理部件形成流水处理
- 用多个冯诺依曼机组成多机系统,支持并行处理
- 从根本上改变冯诺依曼以控制流为驱动,例如采用数据流为驱动
哈佛结构(Harvard Architecture)是一种典型的非冯诺依曼结构,其将指令和数据分开存储到程序存储器和指令存储器中,每个存储器独立编址、独立访问。这样减轻了程序运行时的访存瓶颈,方便了并行处理:
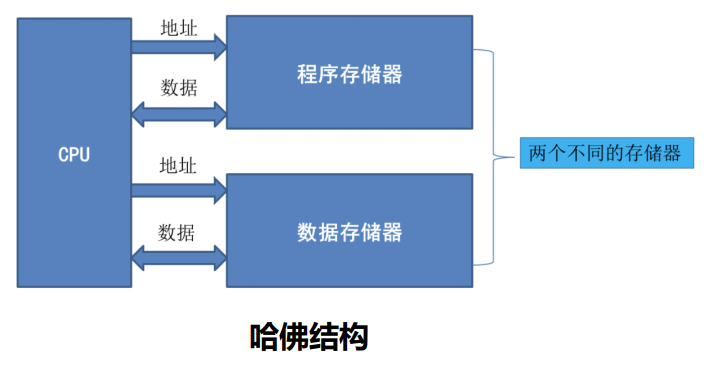
改进哈佛架构则是把两个存储器的地址总线和数据总线进行合并:
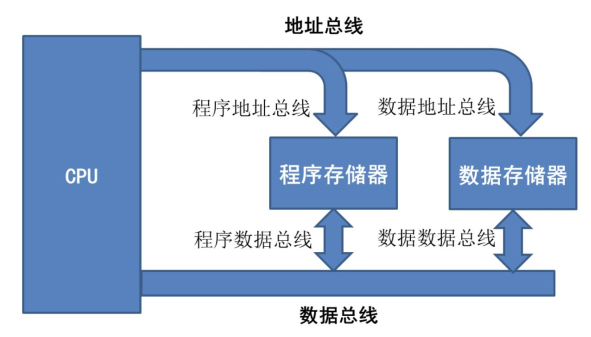
自 ARM9 开始,ARM 使用了哈佛结构的架构,被广泛应用于嵌入式设备和移动设备中。现代通用处理器基本都是内部采用类哈佛结构,外部采用冯诺依曼结构,也即内部的缓存分为指令缓存和数据缓存,外部的存储器则不进行区分。
其他非冯诺依曼架构的计算机还包括数据流计算机、归约机、量子计算机和光子计算机等。
其中数据流计算采用数据流驱动的思想,也即数据就绪就开始运算,打破了传统串行执行指令的思维禁锢。
大数据处理系统的编程模型都倾向于主体采用数据流描述方式。
8、互连网络
8.1、概念与分类
互连网络(Interconnection Network,ICN)是一个在终端之间传递数据的可编程系统。互连网络将各个并行节点之间连接起来,是并行结构的核心。
互连网络依据其规模可以分为:
- 广域网(WAN):全球范围内的连接,连接上百万的设备,物理距离跨度超过数千公里
- 局域网(LAN):一个自治系统内机器的项链,涉及数百台机器,物理距离跨度从几米到几十公里不等
- 系统区域网络(System-Area Network):一台“机器”内的互联,机器可以是一个多核系统,可以是一台超级计算机,物理距离跨度大概在几十米。
- 片上网络(On-Chip Networks):一个芯片上毫米级别元件之间的互联。
互连网络对并行系统而言至关重要,需要经过良好的设计,以支撑短时间内大量数据的传输以及对系统外界提供服务。
8.2、互连网络的设计
互连网络的通信特征包括:
- 延迟必须要低
- 带宽必须要高
- 要传递的消息是许多固定大小的小消息,最大的消息通常是一个缓存块的大小(64 比特或 128 比特)
以上特征影响了互连网络的设计:
- 只有链路和节点两个层次
- 通信协议尽可能简单,没有丢包和复杂的流控制
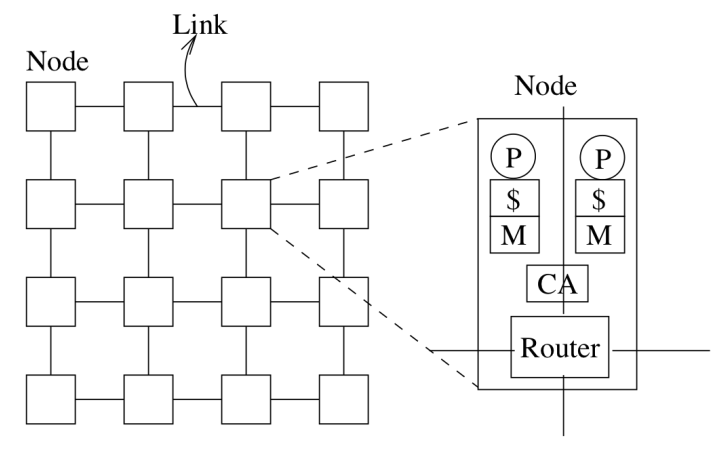
节点(Node)由一个或多个处理器、通信控制器(Communication Assist/Controller, CA)、路由器构成。各个节点的路由器之间被链路连接起来。
链路(Link)是将一对节点之间的导线的集合,可以是单项的也可以是双向的。链路上传输的基本单位称为流量单元(Flit),Flit 的大小由链路延迟和可用缓冲区数量决定。
通道(Channel)由链路、接受端和发送端构成。通过通道传输的数据会被分为一个个包(Packet)。
8.3、互连网络的拓扑
互联网络的拓扑也即互连网络的形状,决定了消息在网络中传递的路径。拓扑的重要特征包括:
- 直径(Diameter),也即网络中两个节点之间最短路径的最大长度
- 平均距离
- 度(Degree),也即每个节点的连接数
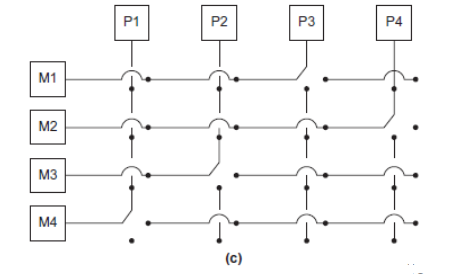
共享内存结构中,互连网络的拓扑结构主要有总线型(Bus Interconnect)和交换型(Switched Interconnect)。
总线型拓扑中,所有通信线路以及其控制的设备都连接到总线上。随着设备树的增加,通信发生碰撞的概率也会增加,从而导致通信效率降低。
交换型拓扑中,利用交换机来控制数据在互联设备之间的传输。例如交换开关(Crossbar Switch),可以允许不同设备之间同时通信。
分布式内存结构中,互连网络包括直接型和间接型。
直接型拓扑中, 交换机直接连接到处理器,交换机之间再相互连接:
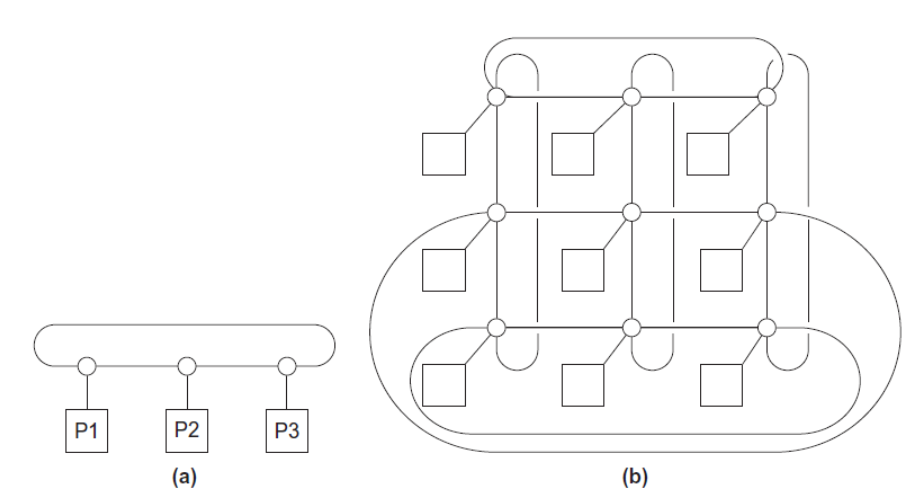
等分宽度(Bisection Width)是指网络中能够同时进行通信的数量,或者说将网络分为两个相等的部分所需要删除的最小链路数量。等分宽度越大,说明能够支持更多节点同时进行通讯,说明网络的性能越好。例如,一个全连接网络的等分宽度为,其中为节点数。
等分带宽则是指将网络分为两个相等的部分时删除掉的链路的总带宽,其越大,说明网络的性能越好。
超立方体型的互连网络,其等分宽度和等分带宽都较高。
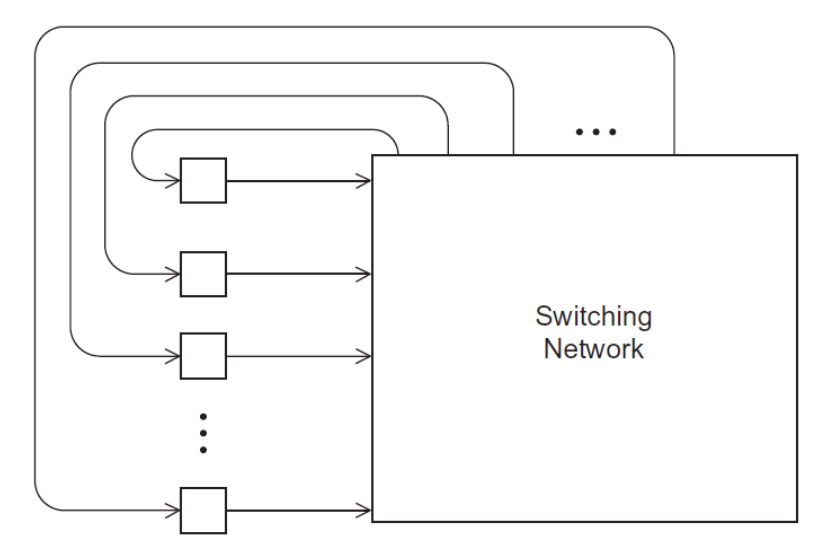
间接型网络中,每个处理器有一条链路连接到交换网络中,交换网络也有一条链路连回处理器:
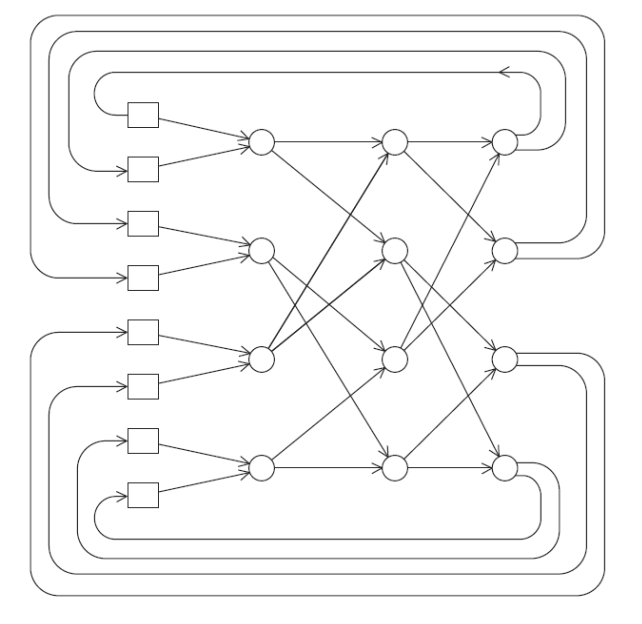
交换网络包括有用交换开关实现的,也有 Omega 网络:
8.4、互连网络中的路由策略
互连网络中传递包的方式包括存储转发和直通两种。
存储转发(Store & Forward)是指在包到达目的地之前,每个节点都会将包存储在自己的缓冲区中,然后再转发给下一个节点。
直通(Cut Through)是指包到达节点后,节点会立即将包转发给下一个节点,不需要等待整个包到达,类似于流水线的方式。
路由策略包括:
-
最小路径:数据包经过最少的跳数。
-
确定性:每个发送-接收对使用单一路径。
-
自适应:消息在传输过程中可以改变路径。
-
死锁处理::由于缓冲区空间有限和循环依赖,网络无法转发数据包,出现思索
9、并行软件
目前并行硬件的发展能够跟上我们的需求,要想取得很好的性能,还需要编写好的并行软件。
共享内存系统上的并行程序,只起一个进程,然后分出若干个线程,每个线程完成一部分任务;分布式内存系统上的并行程序,起多个进程,每个进程完成一部分任务。
编写并行程序,需要将任务分给多个进程/线程,每个进程/线程拿到相同数量的任务,同时最小化进程/线程间所需的通信。同时还要保证进程/线程之间的同步与正常通信。
共享内存系统中运行并行程序,可以用动态线程也可以用静态线程。
- 动态线程(Dynamic Thread)是指只有一个主线程(Master Thread)保持运行,有需要时从中 fork 出新线程。当新线程的任务完成后,会被回收。这种方式可以高效地利用系统资源,但是线程的创建和销毁会带来额外的开销。
- 静态线程(Static Thread)是指有一个线程池,其中的线程在工作完成后不会被回收,除非主动清除。这种方式可以减少线程的创建和销毁开销,但是可能会占用更多的系统资源。
SPMD(Single Program Multiple Data)是一种并行编程模型。一个 SPMD 程序虽然只有一个可执行文件,但是运行起来,像有很多个程序在同时运行。SPMD 程序通过条件分支语句,让不同的线程执行不同的代码,其经典结构用伪代码表示如下:
1 | if (I'm thread process i) |
并行程序中,由于线程的执行顺序不确定,相同的程序可能会导致不同的结果。
这是由于存在竞争条件,也即多个线程同时访问共享资源,导致结果不确定,可以通过加互斥锁等方式解决。
分布式内存系统的并行程序,只有 0 号进程可以访问标准输入流;共享式内存系统的并行程序,只有主线程和 0 号线程可以访问标准输入流。标准输出流和标准错误流,所有的进程/线程都可以访问。
由于线程执行的顺序时不确定的,通常只用一个进程/线程向标准输出流写入数据,其他进程/线程向标准错误流输出调试信息,而且总是要带上进程/线程的编号。
10、加速比与效率
记核数为,用串行程序完成任务所需的时间为,用并行程序完成任务所需的时间为,则加速比(Speedup)定义为:
如果有,也即,则称之为线性加速比(Linear Speedup)。这也就是说,有多少核,就能够加速多少倍,这是最理想的情况。
一个并行程序的效率(Efficiency)定义为:
也即能达到理想的线性加速比的程度。效率越高,说明并行程序的性能越好。
由于总存在一些不可并行的部分,且会有通信之类的开销,所以一般有:
其中就代表了这些不可并行的部分。
假设一个问题有的比例是可并行的,则加速比为:
这就是 Amdahl’s Law。
11、可扩展性
可拓展性是指系统、网络或者软件在问题规模增加时,能够通过投入更多的资源,来提升容量/性能的能力。
强可拓展性(Strong Scalable)是指,在保持问题规模不变的情况下,增加处理器数量,算法或者系统执行的时间相应能够减少。例如处理器数量翻倍,执行时间减半。
强可拓展性关注的是在固定问题规模下,通过增加资源来加速计算,适用于计算密集型任务,目的是为了缩短计算时间。
相对应的,如果增加计算资源的同时,也相应增加问题规模,且不会导致算法/系统效率下降,就说是弱可拓展的(Weak Scalable)。弱可拓展性关注的是在资源增加的同时,能够处理更大规模的问题,保持计算时间稳定。适用于数据密集型任务,目的是为了处理更大规模的问题。
这种情况下,期望算法和系统的效率不随着问题规模的增加而下降。
12、并行程序设计
Foster’s Methodology 是一种并行程序设计方法,其包括:
- 分解(Decomposition):将问题分解为可以独立解决的多个子问题,重点关注能够并行的部分
- 通信(Communication):确定哪些数据需要交换
- 聚合(Aggregation):将较小的任务组合成较大的任务,以减少通信开销和提高计算效率
- 映射(Mapping):将各个子问题映射到进程/线程上。映射应该保证通信开销最小,同时保证每个进程/线程的工作量尽可能均衡
第三讲 MPI
1、MPI 简介
MPI(Message Passing Interface)是一种用于编写并行计算机程序的标准库,主要用于多进程间的通信和数据交换。
MPI 不是一种编程语言,而是一组函数库,主要用于分布式内存体系结构。
MPI 程序的编译指令:
1 | mpicc -o <object file> <source file> |
MPI 程序的运行指令:
1 | mpiexec -n <number of processes> <executable file> |
一个 MPI 程序的基本框架如下:
1 | // ... |
2、Communicator
Communicator,通信域,是能够相互传递消息的一组进程的集合。
MPI_init() 函数会创建一个包含所有进程的通信域,称之为MPI_COMM_WORLD。
MPI_Comm_size()可以获取某个通信域中的进程数,MPI_Comm_rank()可以获取调用这个函数的进程在通信域中的编号。两个函数的函数原型如下:
1 | int MPI_Comm_size(MPI_Comm comm, int *comm_sz_p); |
MPI 函数通常传入一个指针来接收返回值。
2、消息的发送和接收
进程之间的通信用MPI_Send()和MPI_Recv()函数来实现。
发送函数的函数原型如下:
1 | int MPI_Send(void *msg_buf_p, int msg_size, MPI_Datatype msg_type, int dest, int send_tag, MPI_Comm send_comm); |
tag是被发送消息的标识符。MPI_Datatype是 MPI 中的数据类型,例如MPI_INT、MPI_FLOAT等。
接收函数的函数原型如下:
1 | int MPI_Recv(void *msg_buf_p, int msg_size, MPI_Datatype msg_type, int src, int recv_tag, MPI_Comm recv_comm, MPI_Status *status_p); |
MPI_Status是结构体类型,其成员包括:
MPI_SOURCE:消息的发送者(源进程)的编号。MPI_TAG:消息的标签。MPI_ERROR:错误代码,如果接收操作成功,则为 MPI_SUCCESS。
若dest和src相同,send_tag和recv_tag也相同,send_comm和recv_comm也相同,则发送和接受就会匹配起来,消息得以传递。
一个接收者可以在不知道消息大小、消息发送者和消息标签的情况下接收消息。
进程调用MPI_Recv()函数时,自身会被阻塞,直到接收到消息。
MPI_Get_count()用于获取接收到的消息的大小(而不是MPI_send()或MPI_Recv()中的msg_size):
1 | int MPI_Get_count(MPI_Status *status_p, MPI_Datatype msg_type, int *count_p); |
3、输入与输出
对于下面这段程序:
1 |
|
由于进程之间调度的不确定性,每次运行的输出都可能不一样。
所以输入输出时我们一般会进行控制,一般只允许MPI_COMM_WORLD中的 0 号进程进行输入输出。其他进程要输出,通过MPI_Send()将消息发送给 0 号进程,由 0 号进程进行输出。
4、集合通信
Collective Communication,集合通信,是指一组进程之间的通信,这些进程通常是在一个通信域中,例如MPI_COMM_WORLD。
集合通信的特点:
- 全局性:通常涉及一个通信域内的所有进程
- 同步性:所有参与的进程必须同时调用集合通信函数,否则会导致程序挂起或者错误
- 高效性:集合通信通常经过优化,能够利用底层硬件和网络特性,提高通信效率
集合通信是是全局同步的,所有进程必须按照相同的顺序调用集合通信函数。MPI 仅通过调用顺序来匹配(与函数类型无关)集合通信操作,在相同时刻被调用的集合通信函数会被匹配起来。
假如每个进程有一个本地变量,要加起来并输出。我们可以所有的进程将自己本地变量传递给 0 号进程,再由 0 号进程相加,也可以采用树形结构来规约:
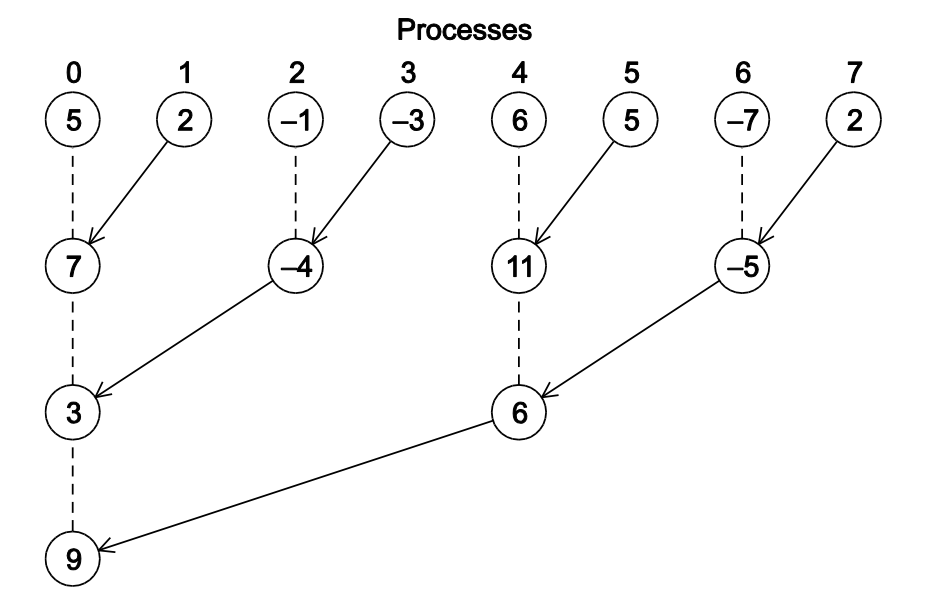
这种将所有进程囊括进去的通信就称为集合通信,例如MPI_Reduce()。而MPI_Send()和MPI_Recv()就是点对点通信(Point-to-Point Communication)。
MPI_Reduce()函数的函数原型如下:
1 | int MPI_Reduce( |
其含义是将所有comm中的input_buf_p中的数据通过op操作规约到dest_proc进程的output_buf_p中。
MPI_Op是一个枚举类型,包括MPI_SUM、MPI_MAX、MPI_MIN等。
根据为了实现合法的规约,所有在同一个通信域中的进程必须调用MPI_Reduce()函数,而且参数之间必须要相容(Compatible)。例如,若规定 0 号进程为最后接受结果的进程,则所有进程的dest_proc参数都应该为 0。而且,最终结果output_buf_p也只有 0 号进程才能使用,其他进程调用MPI_Reduce()时,output_buf_p参数也必须有,即使是空指针。
如果MPI_Reduce()没有被合法的调用或者参数不相容,则程序可能被持续阻塞甚至崩溃。
点对点通信之间通过标签tag和通信域来匹配,而集合通信则是根据通信域和调用的顺序来匹配的。
MPI_Allreduce()的函数原型如下:
1 | int MPI_Allreduce( |
MPI_Allreduce()函数的功能是将comm中的所有进程的input_buf_p中的数据通过op操作规约后,再分发到所有进程的output_buf_p中。可用于进程需要全局结果的情况。
MPI_Bcast()函数的函数原型如下:
1 | int MPI_Bcast( |
MPI_Bcast()函数的功能是将root进程中的data_buf_p中的数据广播到comm中的所有进程的data_buf_p中。
5、数据分配
考虑要并行化向量加法,需要将向量的数据分配给各个进程,通常由三种数据分配的方式:
- 块分配(Block Distribution):将数据分为若干个块,每个块内的数据是连续的,每个进程分配一个块。
- 循环分配(Cyclic Distribution):循环遍历进程,每个进程分配一个数据。
- 块循环分配(Block-Cyclic Distribution):将数据分为若干个块,每个块内的数据是连续的。然后循环遍历进程,每个进程分配一个块,直到所有块分配完毕。
MPI_Scatter()函数的函数原型如下:
1 | int MPI_Scatter( |
MPI_Scatter()函数的功能是将root进程中的send_buf_p中的数据,发给comm内所有进程(包括root进程)的recv_buf_p中,每个进程send_count个。
MPI_Gather()函数的函数原型如下:
1 | int MPI_Gather( |
MPI_Gather()函数的功能是将comm中的所有进程的send_buf_p中的数据,根据send_count和send_type取出,然后收集到dest_proc进程的recv_buf_p中。
MPI_Allgather()函数的函数原型如下:
1 | int MPI_Allgather( |
MPI_Allgather()与MPI_Gather()之间的关系类似于MPI_ALLreduce()与MPI_Reduce()之间的关系。MPI_Allgather()函数的功能是将comm中的所有进程的send_buf_p中的数据按照拼接起来,然后放到所有进程的recv_buf_p中。
6、MPI 衍生类型
类似于 C 语言的结构,可以将几种 MPI 基本类型组合成一个新的数据类型,称之为衍生数据类型(Derived Datatype)。
MPI_Type_create_struct()函数的函数原型如下:
1 | int MPI_Type_create_struct( |
该函数用于创建衍生数据类型,其中blocklengths[]是一个整型数组,blocklengths[i]表示types[i]这个数据类型有几个。displacements[]是一个MPI_Aint类型的数组,表示每个数据类型在该衍生类型中的偏移量;types[]是一个MPI_Datatype类型的数组,表示每个数据类型的类型。
MPI_Get_address()函数的函数原型如下:
1 | int MPI_Get_address( |
MPI_Aint是一个足够大的整数类型,可以储存整个内存空间的地址。MPI_Get_address()函数用于获取location_p指向的变量在内存中的地址,并将其存储到address_p指向的区域中。
MPI_Get_address()常用于计算衍生数据类型中的各个成员的偏移量。
MPI_Type_commit()函数的函数原型如下:
1 | int MPI_Type_commit( |
MPI_Type_commit()函数用于提交一个衍生数据类型,使其可以被使用。之后集合通信函数中,MPI_DataType类型参数可以传入*newtype_p,从而使用这个衍生数据类型。
对应的MPI_Type_free()函数用于释放一个衍生数据类型。
7、性能评估
double MPI_Wtime(void)函数用于获取当前时间,返回一个double类型的浮点数,表示从某个固定时间点到当前时间的时间间隔。
在串行程序中,知道程序的运行时间很简单,只需要在程序开始和结束时分别调用MPI_Wtime()函数,然后计算两者之差即可。
在并行程序中,由于进程调度顺序不同,所以每个进程的运行时间也可能不同。一般来说,我们会取所有进程中的最大值作为程序的运行时间。
int MPI_Barrier(MPI_Comm comm)函数用于同步进程,即等待所有进程都到达这个函数调用的位置,然后再继续执行。它保证,comm中的所有进程都在调用MPI_Barrier()函数时,都会被阻塞,直到所有进程都调用了MPI_Barrier()函数。所以,可以类似下面的代码对并行程序的运行时间进行评估:
1 | //... |
这里,利用了MPI_Barrier()函数来保证所有进程都在同一时间点开始计时,然后通过MPI_Reduce()函数来获取所有进程中的最大运行时间。
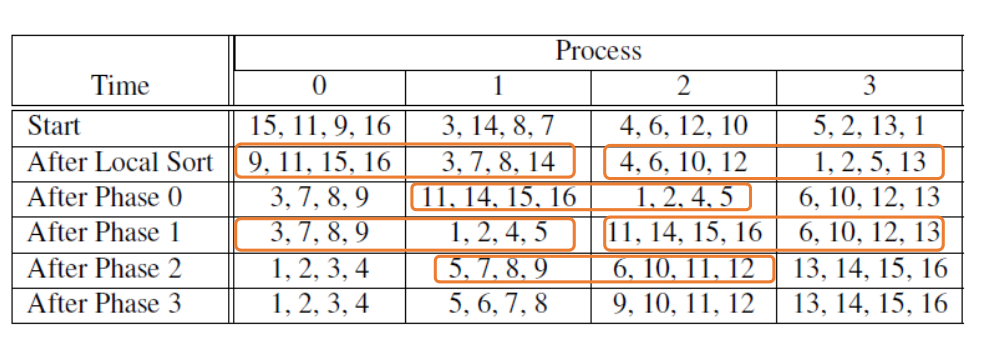
8、并行排序
传统的冒泡排序很难并行化,首先介绍一种新的排序算法:奇偶排序(Odd-Even Sort)。
奇偶排序分为若干轮,从第一轮开始。在第奇数轮中,a[0]和a[1]可以交换,a[2]和a[3]可以交换,以此类推;在第偶数轮中,a[1]和a[2]可以交换,a[3]和a[4]可以交换,以此类推。
将数组平均分给若干个进程,每个进程完成本地数据的排序之后,根据当前的轮数,找到自己的伙伴进程,然后进行数据交换。合并之后,再根据自己的进程号保留较小的部分或者较大的部分。这之中用到的就是奇偶排序的思想。
9、MPI 程序的安全性
MPI 标准允许MPI_Send()有两种行为:
- 将要发送的消息复制到缓冲区中,然后立即返回
- 阻塞,直到对应的
MPI_Recv()被调用
这两种行为都是可以的。
在许多 MPI 实现中,会考虑消息的大小,并设置一个阈值。当消息大小超过这个阈值时,采用缓冲区方式;当消息大小小于这个阈值时,采用阻塞方式。多个进程都采用阻塞方式时,可能会出现死锁。
如果一个程序依赖,由于 MPI 的实现或者使用不当,导致程序在多进程环境下出现未定义行为、数据竞争、死锁或其他错误现象,则这个程序是不安全的。
MPI 标准中定义了MPI_Ssend()来替代,名字中多的一个 s 代表同步(Synchronous)。MPI_Ssend()总是采用阻塞方式。
使用MPI_Ssend()可以固定了发送的行为。但是这样仍然不能避免死锁,还需要合理安排进程的发送和接收顺序,破除循坏依赖等。
MPI_Sendrecv()将阻塞发送和接收结合在一起,变成一个“原子操作”,可以避免死锁。其函数原型如下:
1 | int MPI_Sendrecv( |
第四讲 Pthread 编程
1、Pthread
POSIX(Portable Operating System Interface),也即 Pthreads,是 Unix-like 操作系统的标准,定义了一套用于多线程编程的 API。
一个典型的利用 Pthread 的多线程程序如下:
1 |
|
编译这个程序,需要在编译指令中加入-lpthread参数。
1 | gcc -o <object file> <source file> -lpthread |
pthread_create()的函数原型是:
1 | int pthread_create( |
其中:
thread_p是一个指向线程标识符的指针,对应的空间要在线程创建之前申请start_routine是线程的入口函数,是线程创建后执行的第一个函数arg是传递给start_routine的参数
这里入口函数和入口函数的参数都使用void*类型,可以被转换为任意一种指针。
对于每一个线程,可以调用一次pthread_join()函数,等待线程结束。pthread_join()调用后,会等待对应的线程结束,然后返回。
2、多线程竞争
线程之间是共享全局变量的,可能会出现竞争现象。这种竞争可能导致程序结果出错,或者运行效率降低。
一种解决办法是忙等待(Busy Waiting),即在一个线程中不断检查某个条件是否满足,直到满足为止。这种方法会浪费 CPU 时间,不推荐使用。
另一种方法是使用互斥锁(Mutex)。对某个变量施加互斥锁之后,能够保证在任意时刻只有一个线程能够访问这个变量。
在 Pthread 中:
pthread_mutex_init()用于初始化互斥锁pthread_mutex_lock()用于加锁pthread_mutex_unlock()用于解锁pthread_mutex_destroy()用于销毁互斥锁
当线程数大于核心数时,线程可能被频繁挂起或者处于忙等待状态,此时多线程的效率反而比单线程更低。
忙等待虽然会占用 CPU,但是其延迟比较低,不会涉及内核态的切换。如果对于临界区的操作时间非常短,可以使用忙等待。
互斥锁虽然不会占用 CPU,但是其延迟比较高,会涉及内核态的切换。互斥锁是一个通用场景下的解决方案。
3、信号量
忙等待可以保证线程的执行顺序,但是会浪费 CPU 时间;互斥锁可以保证不会出现竞争现象,但是线程的执行顺序不确定。
有时候,我们既希望避免竞争,也希望能够有序地执行线程(例如计算矩阵链相乘),此时,信号量是一个更好的选择。
互斥锁只允许一个线程进入临界区,而信号量允许多个线程同时进入临界区。
使用信号量需要引入semaphore.h头文件。
创建信号量用sem_init()函数,其函数原型如下:
1 | int sem_init( |
其中shared为 0 时,表示信号在当前进程的多个线程之间共享。value表示信号量的初始值。
销毁信号量用int sem_destroy(sem_t* sem)。
int sem_wait(sem_t* sem)函数用于等待信号量,如果信号量的值大于 0,说明资源可用,则将信号量的值减 1;如果信号量的值为 0,说明资源不可用,信号量的值减 1 后,线程会被阻塞。
int sem_post(sem_t* sem)函数用于释放信号量。如果有线程在等待信号量,会唤醒其中一个线程;否则,直接将信号量的值加 1。
之前提到过栅栏函数MPI_Barrier(),其可以保证所有线程在同一时间点开始执行。
利用忙等待或者互斥锁可以实现栅栏函数。维护一个共享的计数器,用互斥锁保护。线程执行到时,获取锁,给计数器加 1,然后释放锁。最后利用忙等待检查计数器是否等于线程数。
利用信号量也可以实现。用一个初始化为 1 的信号量保护计数器,另一个信号量用来控制线程:
1 | int counter=0; |
条件变量是一种线程同步机制,可以控制线程只有在某个时间时间或者条件成立的时候才能继续执行。
条件变量通常配合互斥锁一起使用。用互斥锁来包裹条件变量,使得检查条件和等待条件的操作是原子的。
利用条件变量也可以实现栅栏函数:
1 | int counter=0; |
其中pthread_cond_wait(&cond_var, &mutex) != 0相当于:
1 | pthread_mutex_unlock(&mutex); |
除了最后一个线程,其他线程都会进入到 while 循环。
- 如果所有线程没有到达,则要被阻塞。首先要释放互斥锁,否则其他线程根本没办法进入临界区。
- 等待条件变量
- 条件变量满足,被唤醒后,要马上重新获取互斥锁,否则会被其他线程抢占。
线程有可能会被不正确唤醒,此时pthread_cond_wait()的返回值不为 0,所以要使用一个 while 循环检查,直到返回值为 0。
4、读写锁
设想多个线程共享一个链表。一个线程尝试寻找链表中是否存在某个元素,另一个线程尝试删除这个元素,这种情况下就有可能出现竞争现象。
容易想到的一种解决方案是对整个链表加锁,任何一个进程对链表进行操作时,都要先获取这个锁。这种做法容易实现,但是如果大部分的操作都是读操作(不改变链表),那么这种做法就会导致效率低下,读操作无法并行化。
另一种解决办法是使用细粒度锁,对链表中的每个节点都有一个锁。首先,这种做法实现起来更复杂,节点多了一个锁,会需要更多存储空间。其次,这样做的效率也比较低,每访问一个节点都要先获取这个节点的锁。
读写锁是一种特殊的锁,包括读锁和写锁。同一时间,可以有多个线程持有读锁,但是只能有一个线程持有写锁。
5、缓存一致性
在多处理器系统时,会出现缓存一致性问题(Cache Coherence Problem)。
其本质是因为每个核心的缓存是独立的,如果一个核心修改了某些数据,并写入到自己的缓存,此时其他核心仍然可能包含旧的数据。如果其他核心继续基于这个旧数据进行操作,就可能导致错误的结果。
伪共享(False Sharing)是一种在多核处理器系统中出现的性能问题。它发生在多个线程访问看似独立的数据时,实际上它们访问的是同一个缓存行中的数据。
这是因为,多核处理器中,每个核心有自己的缓存。当一个进程更新了某个缓存行一个变量,会导致整个缓存行被刷新到主内存,也即这个缓存行失效了。这会影响到其他线程对这个缓存行中其他变量的访问,导致性能下降。
考虑计算:
- 若时,则在上会出现大量的 Write Misses,导致性能下降。
- 若时,则在上会出现大量的 Read Misses,导致性能下降。
- 还是考虑时,但将分给若干个线程进行计算,此时在会被多个线程频繁写,出现伪共享问题。
6、线程安全
一块代码是线程安全的(Thread-Safe),如果其可以被多个线程同时执行而不会出错。
一些 C 标准库里的函数不是线程安全的,例如strtok()函数。根本原因是它们使用了全局变量来保存状态,在多线程环境下,可能会出现竞争现象。
除此之外,还有random()、localtime()等函数也不是线程安全的。
第五讲 OpenMP 编程
1、简介
OpenMP 是一种用于共享内存并行编程的 API,其面向所有线程/进程都能够访问同一块内存的共享内存体系结构。
一个典型的 OpenMP 程序如下:
1 |
|
注意到其中的#pragmas,这是一种特殊的预处理指令,加上它可以允许产生非 C 标准的行为。编译器如果不支持这个指令,则会忽略它。
编译 OpenMP 程序时,需要加上-fopenmp参数。
1 | gcc test.c -o test -fopenmp |
上面提到的#pragma omp parallel是最基本的并行化指令(Parallel Directive),修饰指令的文本称之为子句(Clause),例如后面的num_threads(thread_count)就是一个子句。
加上这个子句之后,会启动指定数量的线程来执行下面的代码块。
注意,能够启动的线程数量取决于系统限制,一般允许启动数百个乃至上千个。用了这个子句不保证能够启动足够数量的线程。
一起执行某块代码的线程集称为是一个线程团队(Team)。原始的线程是主线程(Master),创建出的其他线程为子线程(Slave)。
2、OpenMP 子句
OpenMP 中,变量的作用域与能够访问它的线程有关。如果一个变量能够被一个线程团队中的所有线程访问,则称其有共享作用域(Shared Scope);如果一个变量只能被一个线程访问,则称其有私有作用域(Private Scope)。
在并行块之前定义的变量,默认是共享的。
用critical子句修饰的代码段,同时只有一个线程可以进入执行:
1 | int main(){ |
考虑一个并行的全局求和的程序,如果我们在并行快中用critical子句来保护求和的代码段,相当于退化到串行的情况。
OpenMP 中也存在规约子句:reduction(<operator>: <variable list>)。其中operator是一个二元操作符,例如+、*等;variable list是一个变量列表,表示要进行规约变量,所有子进程的规约变量是相互独立的(一开始的初始化值也都一样),子进程本地的计算结果会临时存储在规约变量中,最后归约到主进程中。
例如:
1 | int main(){ |
假设一共有 10 个线程,则最终在主线程中输出sum,得到的值应该是 14。对于+规约操作而言,规约变量的初始值为 0,十个线程的本地结果都是 1,加起来是 10,最后再与主线程的sum相加,得到 14。
对于*规约操作,规约变量的初始值为 1;&&规约操作,规约变量的初始值为 1(真值)…
for子句可以并行化一个循环。其修饰的代码块必须是一个for循环,它会将循环的不同迭代轮分布到各个线程来实现并行化。
例如:
1 | int i; |
并不是所有的for循环都可以并行化:
- 循环变量必须是一个整数类型或者指针类型
- 循环变量不能在循环体内被修改
- 不同的循环轮之间不能相互依赖(例如在循环体内对共享变量进行修改,在并行的时候可能会出现竞争现象。或者下一个循环要用到上一个循环的结果),OpenMP 不会检查这种依赖。
为了避免循环依赖,可以用private子句。例如一个交替求和的程序:
1 | double sum=0.0; |
还可以用default(none)子句显式要求必须手动指定变量的作用域类型。如果这个子句存在,编译器会检查代码块中的所有变量,确保都显式指定了作用域类型:
1 | double sum=0.0; |
每个循环的计算量可能并不一样,可以使用schedule子句来指定循环分配/调度策略,例如schedule(type, chunksize)。其中type可以是:
static:在循环运行前就分配好了,每个线程轮流拿到chunksize轮进行循环。适用于每轮循环计算量相近的情况。dynamic:在循环运行时分配,每个线程先拿一个,执行结束后再拿下一个guided:也是在循环运行时分配,每个线程先拿若干块,执行结束时再请求,但是请求的数量会减少。这种方式可以使得每个线程的计算量都相对均衡。auto:由编译器或者系统自行决定如何调度(实际上一开始 OpenMP 直接将auto映射到了static上,根本没有实现auto)。runtime:运行时读取OMP_SCHEDULE环境变量,来确定调度策略。OMP_SCHEDULE可以是上述除auto外的任意一个值。
3、生产者消费者模型
生产者消费者模型是一个经典的多线程模型。生产者会“生产”(product)请求,来获取数据或完成某种操作;消费者会“消费”(consume)请求,来找到数据数据返回/产生相应数据/完成某种操作。
生产者和消费者都可以用一个线程表示。每一个线程都有一个具有共享作用域的消息队列(线程团队中的其他线程均可访问)。当一个线程想要向另一个线程发送消息时,就将消息推入(enqueue)另一个线程的消息队列;当一个线程想要接收消息时,就从自己的消息队列里取出一个消息(dequeue)。
在整个程序的开始,主线程接收命令行参数,并且需要为一系列子线程分配消息队列的空间。一部分线程可能提前完成了空间的分配,但是其他线程还没有完成。如果此时尝试向其他线程发消息,就有可能出错。
所以可以利用barrier子句,来保证所有线程都到达了这里才开始执行。
为了保护临界区,还可以使用atomic子句,这个子句只能保护一个简单的赋值操作:
1 |
|
许多处理器都会提供原子的用于完成上面这种语句的加载——修改——存储指令(load-modify-store),这种单一的语句用atomic子句保护,会比critical更高效。
critical子句还有一个具名的版本#pragma omp critical(name),具有不同名字的critical块之间是可以同时执行的。
OpenMP 中也有锁机制,可以用omp_set_clock()和omp_unset_lock()来实现加锁和解锁。
第六讲 并行程序编写实例
1、N 体问题
N 体问题是一个经典的物理学问题,描述了 N 个粒子在相互作用下的运动。求解 N 体问题的基本思路是,根据上一个时间点各粒子的质量、速度和位置,求解加速度,得到一个很短的时间间隔后,各粒子的新位置和新速度。其伪代码如下:
1 | Get input |
第一个计算力的for循环具体如下:
1 | for each particle i { |
根据牛顿第三定律,力的作用力是相互的。如果将粒子之间的相互作用力写为一个矩阵,则这个矩阵是对称的。所以实际上,我们只需要计算一半的力,另一半的结果取负值即可。其伪代码变为下面这样:
1 | for each particle i { |
经过这样处理的问题,称之为简化 N 体问题。
接下来,我们尝试对 N 体问题和简化的 N 体问题进行并行化。
使用 OpenMP 并行化 N 问题
直接对两个循环用#pragma omp parallel for进行并行化:
1 | for each timestep { |
可以发现:
- 对于第一个循环,同一时间最多只会有一个线程访问
force[i],所以不会出现竞争现象。而对速度和位置,只有读操作,也不会有竞争现象。 - 对于第二个循环,每个线程只会写一个一个粒子的速度和位置,也不会有竞争现象。
综上,这种并行化是可行的。
另一种使用#paragma omp parallel for的方式:
1 |
|
这种方式,避免了频繁创建和销毁线程的开销。在内部,会使用同一组线程来执行所有的for循环。潜在的问题是,每个线程都会进行打印。为了避免这种情况,可以用single子句。
1 |
|
用 OpenMP 并行化简化 N 体问题
简化 N 体问题中,第二个循环的每个线程都要访问force[i]和force[j],可能会出现竞争现象。例如在粒子i的循环中,会尝试修改force[i+1],假如在粒子i+1的循环中,也恰好在修改force[i+1],就会出现竞争现象。可以产生用critical子句或者锁来保护,但是都会带来一定的性能开销。
另一种方法是将计算分为两个阶段,第一个阶段,每个线程将自己计算的粒子计算作用力存储在自己的本地数组中,第二个阶段,在遍历每个粒子,从变量中拿出关于这个粒子的力,附加过去。具体代码如下:
1 | // Phase 1 |
由代码可见,这样就避免了竞争现象。
在简化 N 体问题中,如果静态调度,前几个线程会拿到序号较小的粒子,要计算的力就特别多,会造成线程之间的工作量不平衡。如果采用动态调度,线程的工作量就会更平衡些。
使用 Pthreads 并行化(简化)N 体问题。
并行化的思路和 OpenMP 一样其实差不多,但是由于 Pthreads 的特性,会需要手动给线程传递数据,手动指定每个线程计算哪些粒子的数据。
同时,OpenMP 在parrallel块之后,会有隐式的barrier,而 Pthreads 就需要我们显式设置,来保证每一轮所有粒子都计算完毕后,再进入下一轮。
用 MPI 并行化 N 体问题。
使用 MPI,就要考虑各个进程之间如何传递消息了。每个进程负责计算几个粒子,则进程还需要知道其他粒子的位置,计算出作用力之后,还要传递给其他进程。那消息传递可能像下面这样,十分复杂:
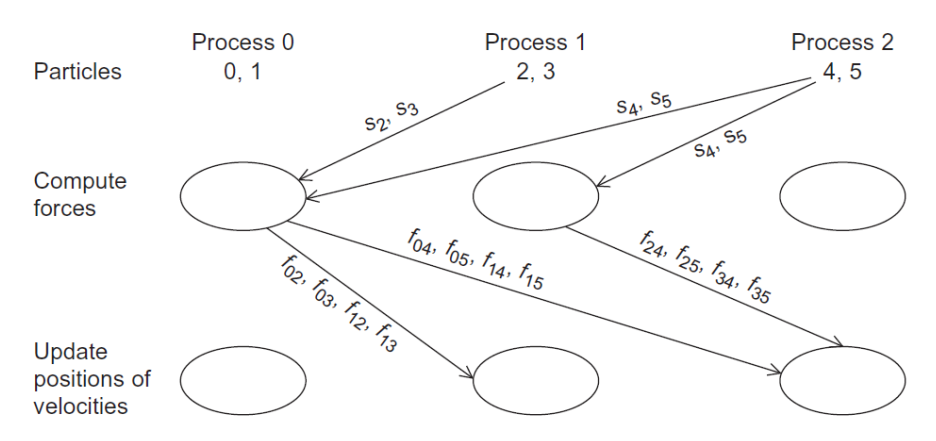
这时,我们可以采用环形传递,每一轮将数据传递给环上相邻的进程,知道所有进程都拿到了所有的数据,如下图所示:
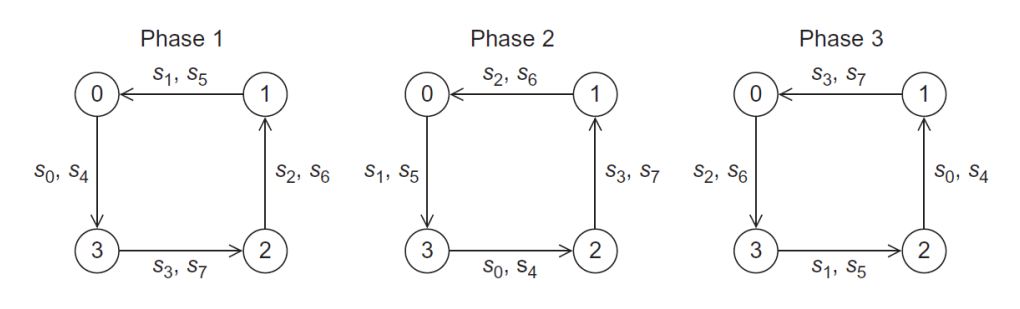
其伪代码如下所示:
1 | source_proc=(my_rank+1)%comm_sz; |
2、TSP 问题
TSP 问题(Tree Search Problem),是一个 NP 完全问题,没有一种在任意情况下都比暴力搜索更好的方法。旅行商问题也是一种 TSP 问题。
对于旅行商问题,一种经典的做法是深度优先搜索+递归,也可以用栈改写为迭代形式。特别地,迭代形式的栈中,每个元素都是一条完整的路线时,非常适合进行并行化。
我们一般会用一个全局变量来保存最优的路线,在并行环境下,我们需要确保对最优路线更新不会出现竞争条件,且要是正确的。
考虑有两个线程同时准备更新这个全局变量,第一个线程与当前最优进行比较,开始更新,但是与此同时,第二个线程已经在执行更新了,且其路线比第一个线程的要更好。由于第一个线程依照之前的测试结果,将自己的路线覆盖过去,这就导致了结果出错。
为了避免这种情况,第一次测试之后,如果要更新先加锁,加完锁之后再测试一遍,避免在测试和加锁之间已经被别的线程修改过了。
静态并行化。一个线程用 BFS 生成开头,然后分配给其他线程去拓展。
利用 MPI 实现静态并行化时,首先由进程 0 读入邻接矩阵,然后boradcast到所有进程。接着又进程 0 略微拓展一下搜索树,并将节点分配给其他进程。其他进程继续拓展搜索树时,要注意检查并更新最优线路的值,当程序终止时,要保证进程 0 拿到最优线路。
由于进程 0 拓展出的节点不一定能被平分,MPI_Scatter和MPI_Gather不一定适用。可以用MPI_Scatterv和MPI_Gatherv,多了一个偏移量参数,可以自由指定数据的范围。
要更新最优线路时,一种方法是用MPI_Bcast,广播到所有线程。但是用这种方法时,通信子内的所有线程都要调用MPI_Bcast,否则会导致进程阻塞。另一种方法是用MPI_Send发送到所有线程,目标线程周期性的接收检查是否有新的消息。但是目标线程不能用MPI_Recv去检查,因为一旦没有新消息,就会被阻塞到下一个消息到来。
可以用MPI_Iprobe,这个函数检查是否有可被接收的消息,但是不会真的去接收消息:
1 | int MPI_Iprobe( |
其中flag用于接收返回值,表示是否有可接收的消息。
MPI 提供了四种发送函数:
MPI_Send:标准模式。实际的 MPI 实现决定了是复制内容到缓冲区,还是直接发送到目标进程。发送者会被阻塞,直到接收者调用MPI_Recv。MPI_Ssend:同步模式。发送者会被阻塞,直到接收者调用MPI_Recv。MPI_Rsend:准备模式。发送者不会被阻塞,接收者必须在发送者调用MPI_Rsend之前调用MPI_Recv。如果没有接收者,发送者会报错。MPI_Bsend:缓冲模式。如果接收者没有准备好,发送者会将消息复制到缓冲区中。发送者不会被阻塞。缓冲区由用户提供给,MPI 不会自动分配。
动态并行化。一个线程将自己的都扩展完之后(栈空),期待从其他线程接到任务。一个线程如果自己有可以分出去的任务,就将自己的任务分配出去(分割栈)。
可以利用条件变量机制,例如 Pthreads 里的pthread_cond_wait、pthread_cond_signal等。其代码如下:
1 | if (my_stack_size >= 2 && threads_in_cond_wait > 0 && new_stack == NULL) { |
第七讲 数据并行体系结构
1、引入
SIMD 有以下特点:
- 可以为矩阵计算和图片/声音处理等运算带来显著的数据并行性提升
- 比 MIMD 更加节能,因为是单指令多数据的,所以适用于个人移动设备
- SIMD 仍然可以让程序员“串行”的思考,通过一条指令处理多个数据来做到并行化
SIMD 有三种具体的实现方式——向量架构(向量计算机)、多媒体 SIMD 指令拓展集、GPU。对于 x86 处理器而言,随着技术进步,核数以及 SIMD 带宽不断增加,SIMD 带来的加速比也越来越高。
2、向量架构
2.1、向量计算机
在 70~80 年代,超级计算机就等于向量计算机。1976 年,世界上第一台向量计算机 Cray-1 诞生,其架构图如下:
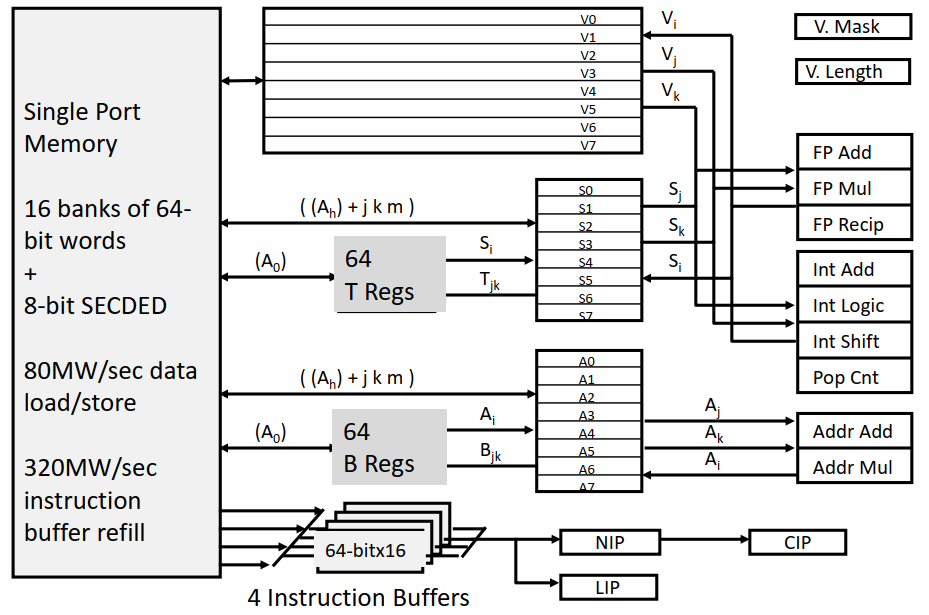
向量计算机的基本思想是,讲数据元素放到向量寄存器(Vector Register)中,然后通过操作这些寄存器,再将结果返回到内存中。
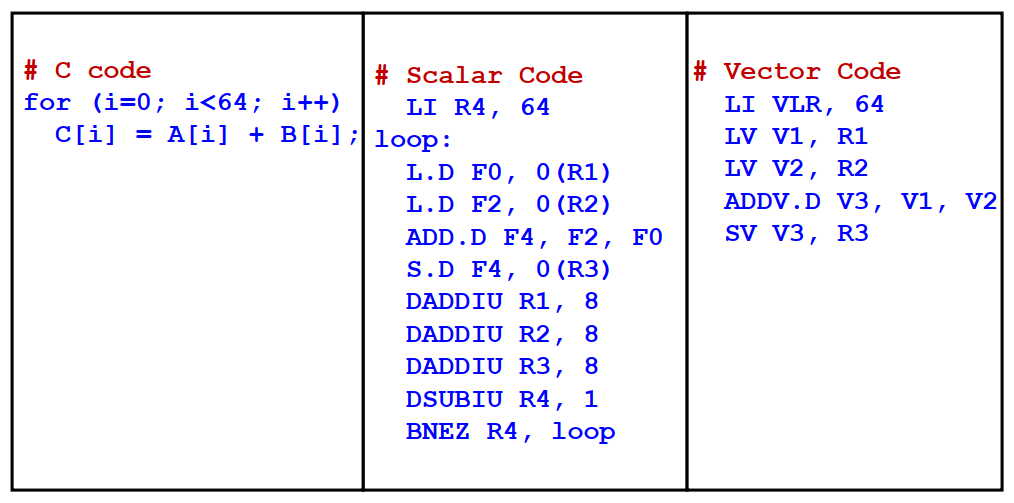
由于可以直接操作向量,实现同一个功能时,其所需的指令数要小得多:
向量计算机通常使用较深的流水线,从而可以同时处理更多的元素,提高吞吐量。同时向量计算机的流水线控制也相对简单,因为向量元素之间的运算通常是相对独立的,很少有冒险情况。
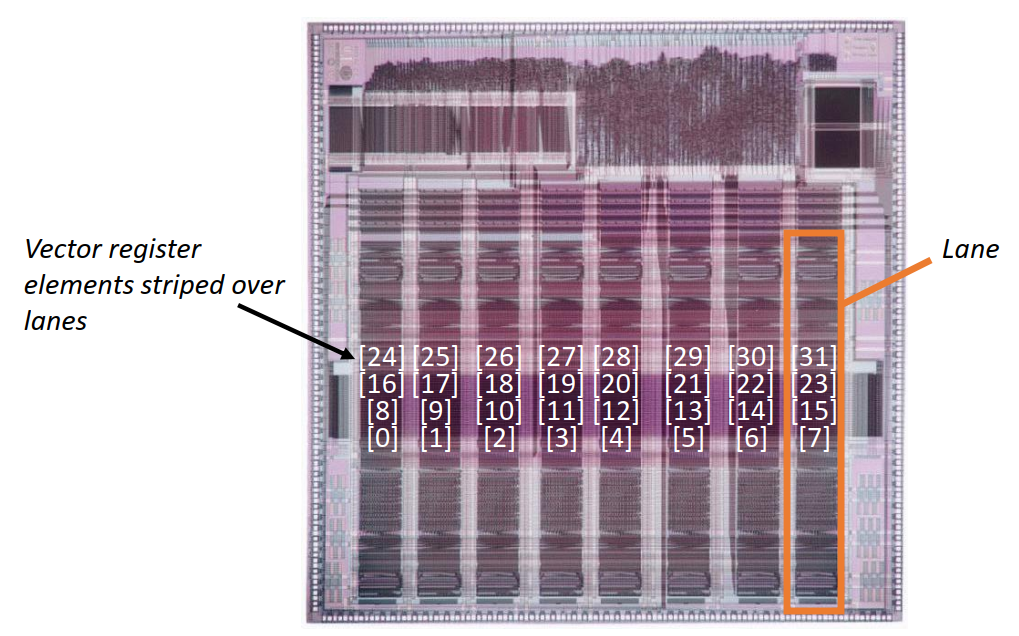
向量计算机处理器,通过堆叠功能部件,来实现向量操作:
2.2、RV64V
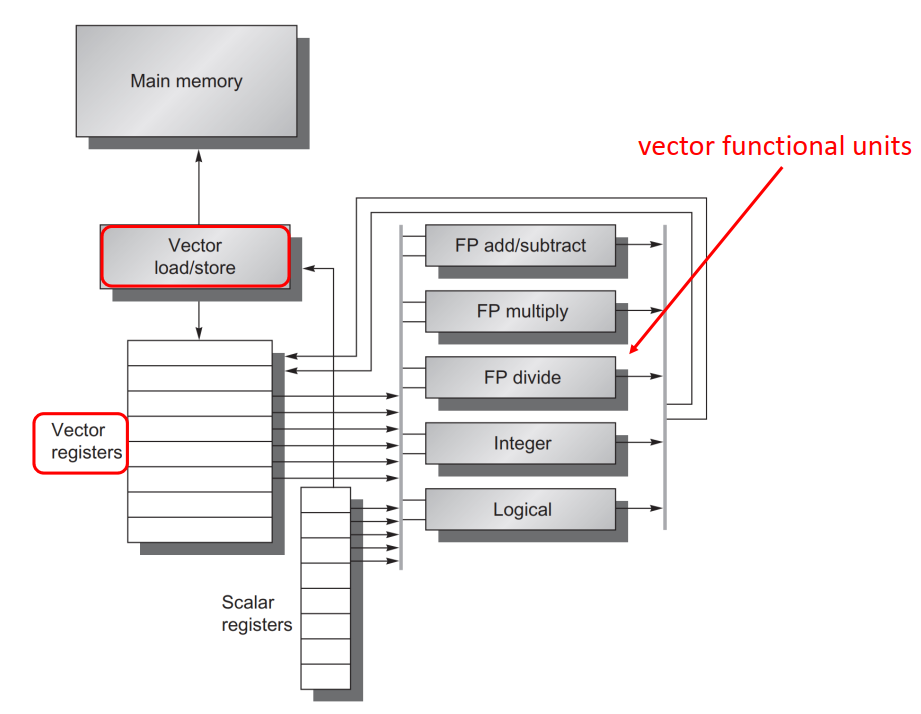
RV64V,也即 RISC-V 指令集加上向量拓展。这个指令架构中,包含 32/64 位的向量寄存器以及向量功能/存取单元,以及普通的标量寄存器:
RV64V 指令用后缀来指示操作数类型。例如.vv是两个向量的操作,.vs是一个向量和一个标量。
一个实现的 RV64V 的汇编程序如下:
1 | vsetdcfg4*FP64 # Enable 4 DP FP vregs |
向量指令的执行时间依赖于三个因素:操作向量的长度、指令之间的冒险、数据以来关系。RV64V 的功能单元一个时钟周期可以处理一个元素,所以 RV64V 程序的执行时间近似与向量长度成正比。
2.3、Convoy
Convoy 本意是船队或车队的意思,在这里指一组能够被同时执行(在同一条流水线中依次执行)的向量指令。同一个 Convoy 内的指令不能出现任何的结构冒险。
一个例外是 read-after-write 类型的冒险,可以通过 Chaining 来解决,从而放在同一个 convoy 中。所谓的 chaining 实际上就是计算机组成原理中提到的旁路(Bypassing)。
具体来说,就是讲上一条指令的结果,下一条指令就要用,可以直接传递到下一条指令的功能单元中,而不必等到被放到目的寄存器中然后再取出来。
2.4、Strip Mining
实际程序中,向量的长度一般都是不能在编译时就确定的,例如需要手动输入向量的维度。
针对这种情况,解决方法是引入向量长度寄存器vl,vl控制者任何向量操作涉及的向量长度。vl的值不能超过最大向量长度(maximum vector length,mvl)。
如果大于 mvl,就会分条带处理(Strip Mining),一个循环用于处理 mvl 的整数倍的部分,另一个循环用于处理剩下的部分(这部分的维度一定小于 mvl)。
RISC-V 中提供了setvl指令:
- 比 mvl 大时,会把
vl的值设置为 mvl - 比 mvl 小时,会把
vl的值直接设置为
2.5、向量条件执行
当程序在循环中包含 if 等条件判断语句时,是不便于向量化的,例如:
1 | for(int i=0; i<64; i++) |
如果某个x[i]不等于 0,则这一段不能直接向量化。
为了引入这个问题,引入了向量掩码控制(Vector Mask Control),使用断言寄存器(Predicate Register)来存储一个布尔类型的向量,从而控制一个向量指令中,有哪些元素是需要被操作的。只有元素对应的断言寄存器上的值为 1 时,才会被操作。
一段使用断言寄存器的代码如下:
1 | vsetdcfg 2*FP64 # Enable 2 64b FP vector regs |
2.6、向量内存子系统
向量架构中,为了存取向量,内存系统必须被设计为支持高带宽的内存访问,同时对各个内存 bank 的访问应该是相互独立的。
例如 Cray-1 的内存系统如下图所示:
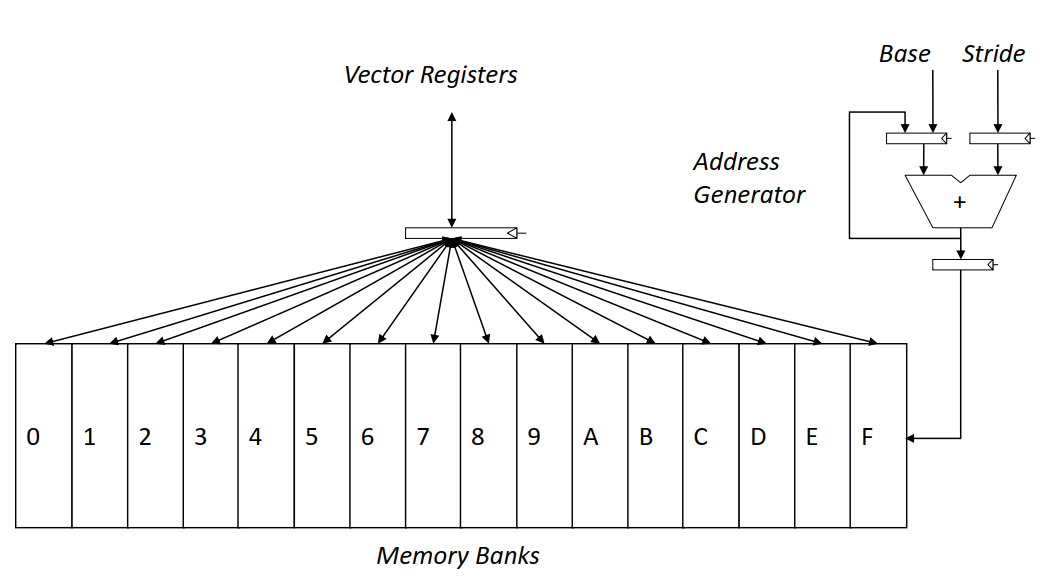
内存到内存的向量架构(Vector Memory-Memory Architecture,VMMA)将所有的操作数都放到内存中:
1 | ADDV C, A, B |
相对的,寄存器的向量架构(Vector Register Architectures)将操作数放到寄存器中完成运算:
1 | LV V1, A |
相较而言,VMMA 需要更大的内存带宽,所有的操作数先要从内存中读出/写入到内存。VMMA 架构中,也很难实现多向量操作的并行,因为需要检查内存地址相关的依赖。所以后来的向量计算机都使用寄存器的向量架构。
2.7、处理多维数组
多维数组中逻辑上“相邻”的元素,在内存中不一定相邻。例如在行优先架构中,A[i][j]和A[i+1][j]虽然在逻辑上是相邻的,但是在内存中并不相邻。
例如在做矩阵乘法时,常会遇到A[i][j]=A[i][j]+B[i][k]*C[k][j]的情况,遍历k时,对C的访问在物理内存中就不是连续的。
大于 1 的步长(Stride)就称为非单位步长(Non-unit Stride)。向量架构中,允许直接以指定步长从内存中加载/写入数据到寄存器(也即将内存中不连续的元素先拼成一个紧的向量,再操作)。
可能会频繁访问内存的同一个 bank,在这个过程中,可能会出现冲突。
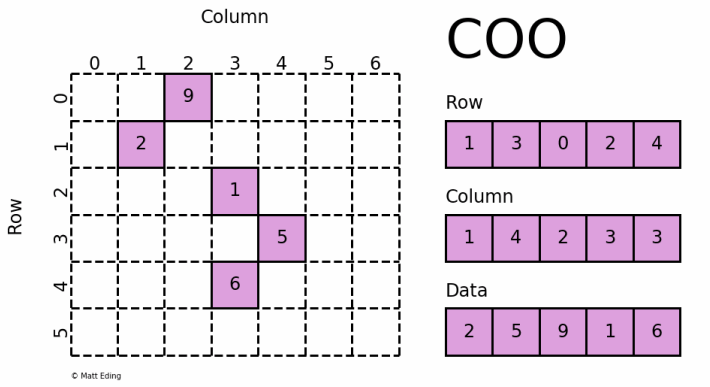
2.8、处理稀疏矩阵
对于系数矩阵,可以存储为一个更紧密的形式,例如 COO(Coordinate)格式:
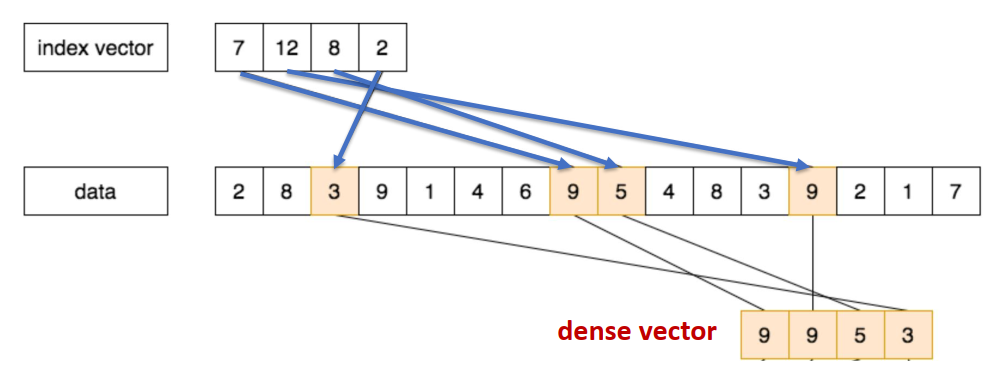
通过额外的索引向量,可以先读取并拼接为一个紧的向量,再放到寄存器中进行处理:
一段具体的汇编代码如下所示:
1 | vsetdcfg 4*FP64 # 4 64b FP vector regs |
3、多媒体 SIMD 指令集拓展
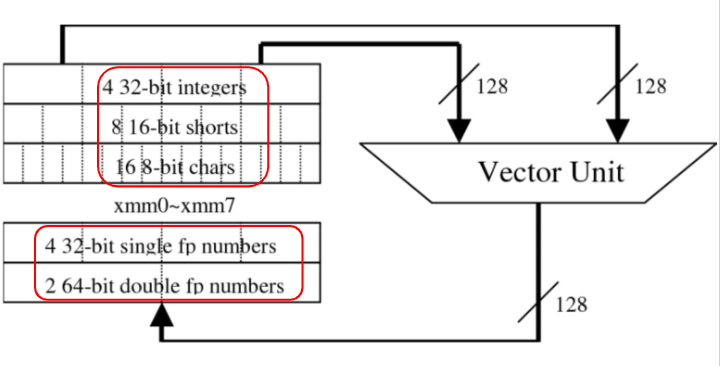
许多多媒体应用的数据,操作的数据通常都是更短的向量,例如图形学中 8bits 的颜色值,或者 16bits 的音频数据。
SIMD 拓展指令集中,通过进行划分,处理器可以利用 256 位的加法器,同时操作 32 个 8bits 数据的相加:
相较于向量计算机的原生支持,多媒体 SIMD 指令集拓展有以下限制:
- 操作数中固定要用
#标注 - 不支持复杂的寻址模式
- 不支持向量掩码控制,所以不支持条件执行
具体的 SIMD 拓展实现包括:Intel MMX、SSE(Streaming SIMD Extensions)、AVX(Advanced Vector Extensions)、AVX-512 等。
4、GPU
4.1、引入
GPU(Graphics Processing Unit)的设计和提出基于异构计算模型:CPU 作为主机(Host),GPU 作为设备(Device),两者协同工作。
CUDA 是一种专为 GPU 设计的类 C 语言,CUDA 线程集中体现了 GPU 的并行性。GPU 的编程模型是 SIMT。
GPU 架构与向量机相比:
-
相似之处
- 都在数据级并行化问题上表现良好
- 都支持散射-聚集传输、掩码寄存器和大型寄存器文件
-
不同之处:
- GPU 通过多线程隐藏内存延迟
- GPU 拥有大量功能单元,而不像向量处理器拥有少而深流水线的单元
4.2、异构计算
异构计算(Heterogeneous Computing)是使用多种不同类型/架构的处理器(如 CPU、GPU、FPGA 等)来完成计算任务。与之相对的,同构计算(Homogeneous Computing)是使用同种类型的处理器来完成计算任务。
异构计算可以将任务分配给最适合的处理器,从而提高性能和能效。
一种经典的异构计算节点的设计是,两个多核 CPU+多核 GPU:
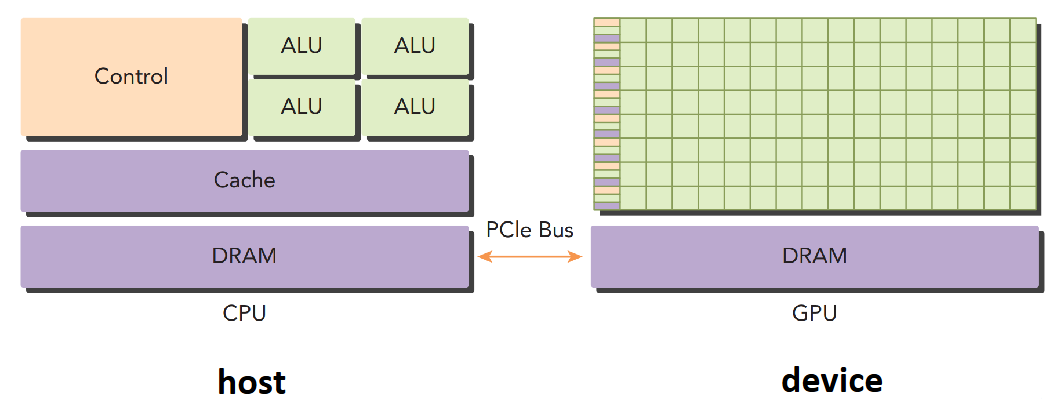
异构架构的应用通常分为主机代码(Host Code)和设备代码(Device Code)。主机代码在 CPU 上运行,,设备代码在 GPU 上运行。CPU 计算非常适合控制密集型任务,GPU 计算非常适合数据并行计算密集型任务。GPU 在异构计算中用于实现数据并行计算,这也被称为硬件加速。
GPU 也有线程的概念。CPU 的线程通常是一个“重量级”实体,操作系统需要轮转调度线程,实现宏观上的多线程并行效果。也因此,CPU 的线程通常是比较少的,通常在 4~16 个之间。GPU 的线程则是极度轻量化的,现代 NVIDIA GPU 可在每个 core 上支持上千个线程。
第八讲 CUDA 简介
1、CUDA
CUDA(Compute Unified Device Architecture)是一个通用并行计算平台和编程模型。CUDA 利用 NVIDIA GPU 中的平行计算引擎来解决许多复杂的计算问题,你可以在利用 CUDA 编写程序利用 GPU,就像用 C/C++编写程序利用 CPU 一样。
CUDA C 是标准 C 语言的拓展,通过少量的语言拓展提供了对异构编程的支持,同时拥有直接访问控制硬件设备、内存等的 API。
CUDA 提供了两种 API:
- CUDA Driver API:低层次的 API,提供了对底层 GPU 设备的直接控制,适合需要精细控制 GPU 资源的应用,相对也更难使用。
- CUDA Runtime API:高层次的 API,基于顶层 Driver API 实现。Runtime API 中的每个函数在执行时,会被拆分为多个基本的 Driver API 操作。
CUDA 的源代码文件后缀为.cu,用 nvcc 编译器编译:
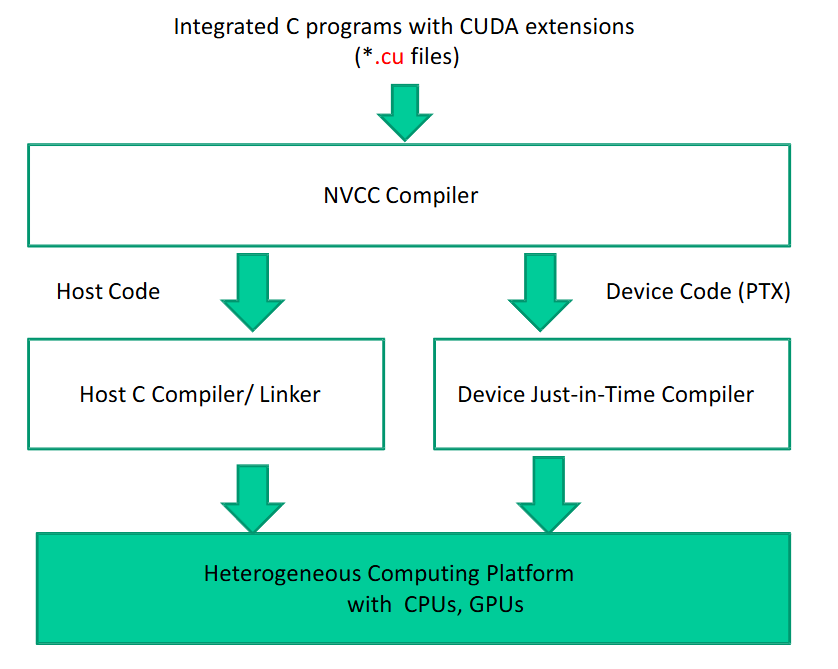
一个基本的 CUDA 程序如下:
1 |
|
在 Pthreads 或者 OpenMP 中,需要显示地创建和控制线程。利用 CUDA C 进行编程时,线程的创建和控制是隐式的。只需要编写一段串行代码,然后 GPU 会自行用多个线程来调用这个核函数。
2、CUDA 编程模型
编程模型是一种计算机体系结构的抽象,充当应用程序及其实现之间的桥梁。
从程序员的角度来看,并行计算有多种不同的级别:
- 域级别(Domain Level):如何分解数据和功能以解决问题
- 逻辑级别(Logical Level):如何组织并发线程
- 硬件级别(Hardware Level):线程如何映射到核心可以帮助提高性能
CUDA 通过层次结构,提供了一种控制 GPU 上的线程以及对 GPU 内存的访问方式。在 CUDA 中,GPU 被视为计算设备,能够并行执行大量的线程。GPU 作为 CPU 的协处理器(coprocessor),CPU 上运行的应用程序的计算密集型部分会被加载(off-load)到 GPU 上。
CUDA Kernel 是程序员编写的某个函数/程序,会被放在 GPU 线程上运行。具体而言,应用程序的并行部分可以剥离为在 GPU 上很多不同线程上执行的函数,将这样的函数编译得到的 GPU 指令以及程序,就称为内核(Kernel)。
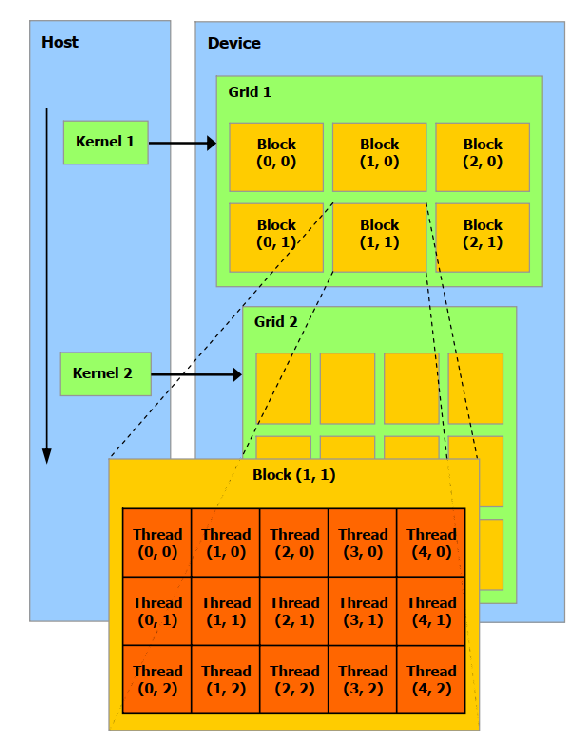
一组执行同一个 Kernel 的线程,被组织为若干个线程块(Block)组成的网格(Grid),每个线程块又包含若干个线程:
2.1、CUDA 内存管理
一个典型的 CUDA 程序的结构一般分为五个步骤:
- 申请分配 GPU 内存
- 将数据从 CPU 内存拷贝到 GPU 内存
- 在 GPU 上执行核函数
- 将数据从 GPU 内存拷贝回 CPU 内存
- 释放 GPU 内存
CPU 内存与 GPU 内存之间通过 PCIe 总线连接。
CUDA 编程模型假设系统由一个 Host 和一个 Device 组成。每个部分都有独立的内存。CUDA 另一个显著的特点就是暴露了内存的层级。每个 GPU 设备都有一组不同类型的内存:
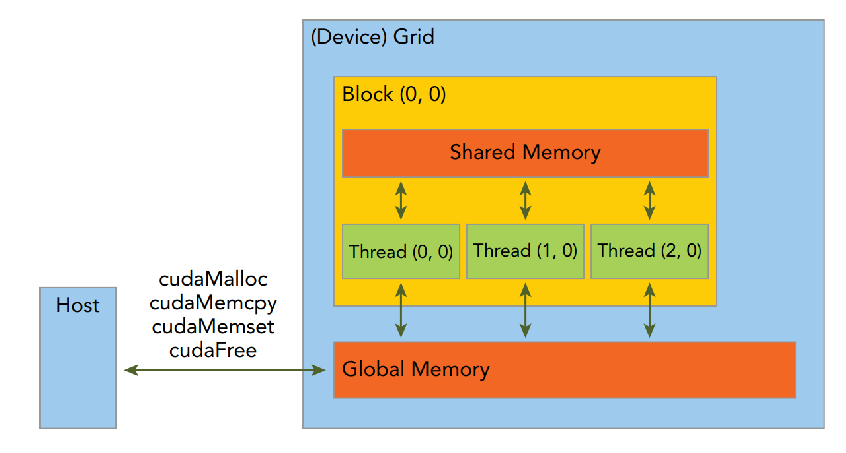
其中 Global Memory 是 GPU 的主内存,用于 Host 和 Device 之间的通信,可被同一个 Grid 内的 GPU 线程访问,但是访问速度较慢。每个线程也有自己的寄存器,同一个 Block 内还有共享内存(Shared Memory)。
CUDA Runtime API 提供了一系列内存管理函数:
cudaMalloc():在 GPU 的 Global Memory 中分配内存cudaFree():释放 GPU 的 Global Memory 中的内存cudaMemcpy():拷贝数据,其中最后一个参数指定了传输的类型(Host to Device、Device to Host、Device to Device 等)
尤其要注意,GPU 内存和 CPU 内存不是一个空间,不能再 Host Code 中对 GPU 内存指针解引用,也不能将 CPU 内存指针传递给 GPU 内存指针。
2.2、CUDA 线程组织
单个核启动产生的所有线程被称为一个 Grid,它们共享同一个 Global Memory,一个 Grid 是由很多个 Block 组成的。
同一个 Block 内的线程相互合作,不同 Block 内的线程不能直接合作。一个 Gird 内的线程通过blockIdx和threadIdx唯一表示。blockIdx和threadIdx是内置的遍历,在启动时由 CUDA Runtime 自动分配。它们的类型都是uint3类型,最多支持 3 维。
启动核函数的语句如kernel_routine<<<gridDim, blockDim>>>(args),其中gridDim表示 Grid 的维度,blockDim表示 Block 的维度。gridDim和blockDim都是dim3类型的变量,表示一个三维的向量。未被指定的维数默认是 1,会被忽略。
通过指定gridDim和blockDim不仅指定了一个核函数的线程数,还指定了线程的布局。两个维度是有上限的,取决于具体的设备。
CUDA 核函数的启动是异步的,也即,函数启动后,控制会立刻回到 CPU。
2.3、编写核函数
核函数是在 Device 上执行的代码,用__global__来修饰。核函数中,定义的是“单个线程”的计算核数据处理。
函数类型限定符有三种:
__global__:表示该函数在 Device 上执行,并且可以被 Host 调用,返回类型必须为void__device__:表示该函数在 Device 上执行,并且只能被 Device 调用__host__:表示该函数在 Host 上执行,并且只能被 Host 调用
核函数除了返回值类型必须是void之外,只能访问 Device 的内存,同时不支持变长参数、静态变量、函数指针等。
记录 CPU 挂钟时间,可以用gettimeofday()函数。将其封装为下面这个cpuSecond()函数:
1 | double cpuSecond() { |
然后就可以像下面这样去调用:
1 | double iStart = cpuSecond(); |
还可以用 nvprof 工具,这是一个命令行的 CUDA 程序分析工具。nvprof 可以分析 CUDA 程序的性能瓶颈,给出每个核函数的执行时间、内存传输时间等信息。例如,用nvprof ./your_program。
由于核函数中定义的是单个线程的操作,要实现并行,不同的线程要操作不同的数据。怎样让线程知道自己要操作哪个位置的数据?
由于blockIdx和threadIdx由 CUDA Runtime 分配,是已知的,所以可以通过它们来计算出每个线程要操作的数据位置。例如两个数组求和的并行,核函数里就可以这样写:
1 | __global__ void add(int *a, int *b, int *c) { |
不同规模的 Gird 和 Block,会对程序的性能产生影响,并不是越大越好,需要根据具体的应用来选择。
3、CUDA 执行模型
GPU 的架构图如下:
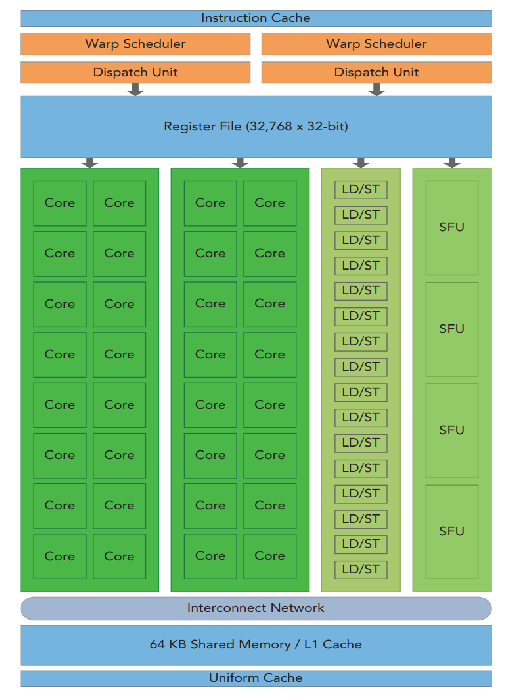
其硬件并行化时通过大量堆叠流式多处理器(Streaming Multiprocessor,SM)阵列来实现的。
SM 设计出来就是为了支持大量线程的并发。当一个核函数启动时,其每个 Block 就会被分配到某个空闲的 SM 上执行。
3.1、Warp
CUDA 是一种 SIMT 架构,其调度的基本单位是包含 32 个线程的 Warp(线程束)。一个 Warp 中的所有的线程在相同的时间执行相同的指令,但是由于每个指令有自己的寄存器状态和地址计数器,所以可以操作不同的数据。Block 会被分为多个 Warp 来调度和执行。每个线程最终在一个 CUDA 核心上执行。
CUDA 的 SIMT 与 SIMD 的区别在于,SIMT 允许同一个 Warp 内的不同线程相对独立地执行,而 SIMD 则必须是所有线程“齐头并进”一起执行。
同一个 Block 内的 Warp,可能在 SM 内以任意顺序被调度。完成后,会被释放,新的 Warp 会被 SM 调度执行。Warp 之间的切换是没有开销的,SM 中已经存储了 Warp 的状态信息。
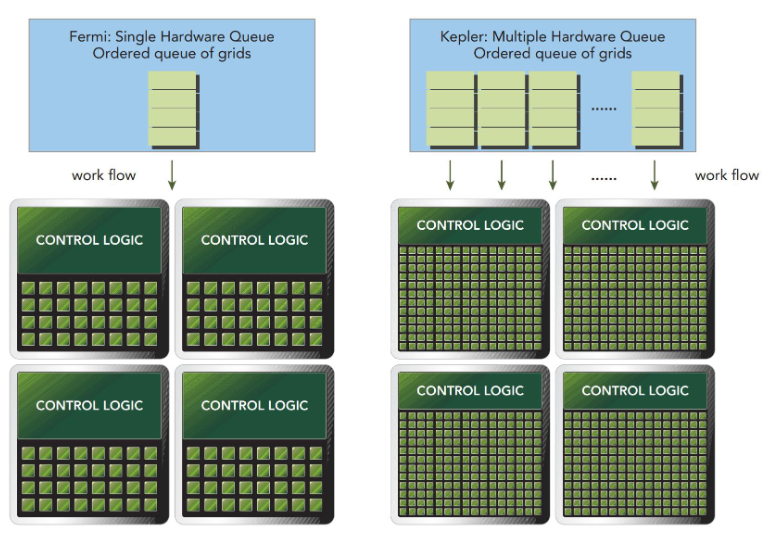
Fermi GPU 架构如下:
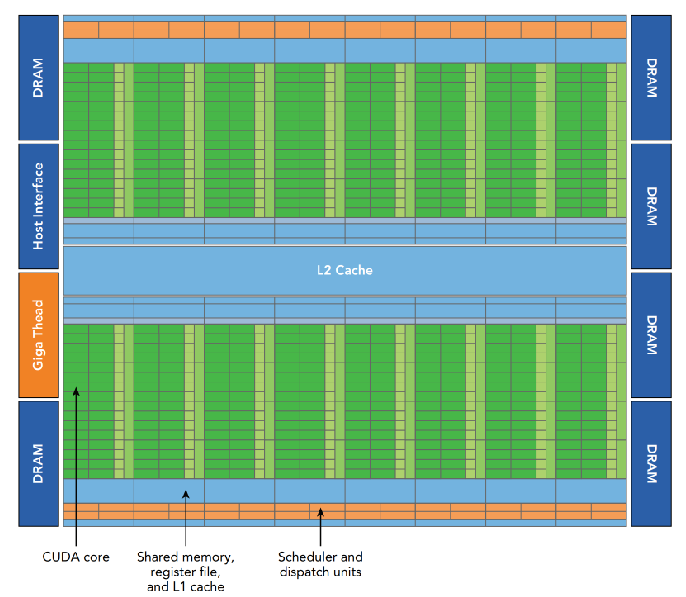
其有 16 个 SM,每个 SM 有 32 个 CUDA 核心,2 个 Warp 调度器和 2 个指令调度单元。Fermi 架构中的一个 SM 可以同时调度 48 个 Warp,共 1536 个线程。
Fermi 架构的一个核心特性,是有 64KB 的片上可配置内存,可以被自由划分为共享内存或者 L1 缓存。CUDA 提供运行时 API 来调整这部分内存的划分。
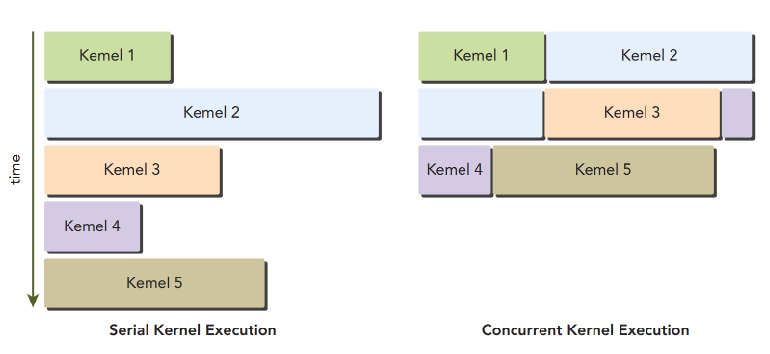
Fermi 还支持核函数并发执行(Concurrent Kernel Execution)。同一个程序启动的多个核函数可以同时被调度:
Kepler 架构有 15 个 SM,每个 SM 有 4 个 Warp 调度器和 8 个指令调度单元。每个 SM 可以调度 6 个 Warp,共 2048 个线程。
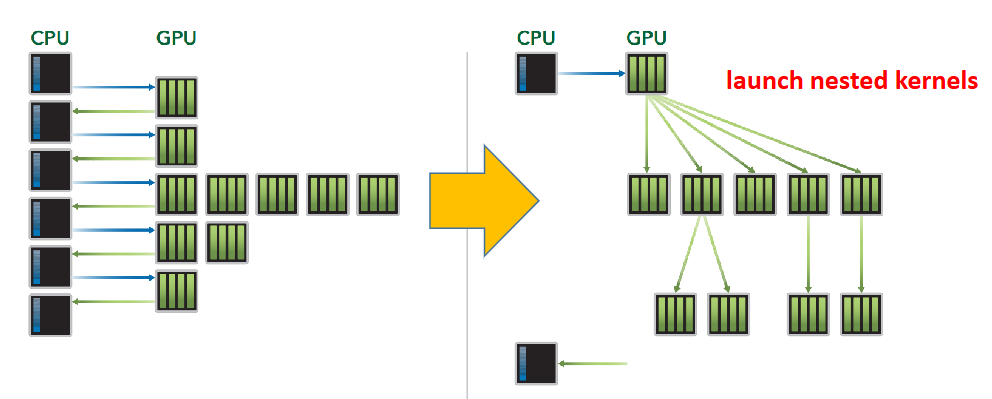
Kepler 架构的特性是支持动态并行化,也即允许 GPU 动态启动新的 Grid,换句话说每个核函数可以嵌套地启动新的核函数,并且自动控制核函数之间的依赖:
Kepler 架构还支持 Hyper-Q 特性,一共设置了 32 个硬件工作队列,允许 CPU 同时向 GPU 提交多个任务,避免了队头堵塞的问题:
3.2、Profiling
分析(Profiling)是分析程序性能的过程,也是编写一个优秀并行程序的关键过程。Profiling 会分析程序的:
- 内存占用或者时间复杂度
- 特定指令的执行次数(热点)
- 函数调用的频率核执行时间等
CUDA 提供了两个基本的工具,nvvp以及nvprof。
3.3、Warp 执行
Warp 是 SM 的基本执行单元,每个 Warp 包含 32 个线程。一个核函数的 Grid 中的若干个 Block 会被分配到 SM 上执行。当一个 Block 被分配到某一个 SM 上后,会被进一步分为多个 Warp。
虽然 Block 可以至多有三维,但是对于硬件来说,最终还是被拍平为以为的“线程数组”,然后 32 个线程为一组,组成一个 Warp。
之前已经提到,一个 Warp 内的所有线程,在同一个时钟周期内,应该执行相同的指令。如果存在两个线程在执行不同的指令,就是出现了 Warp Divergence(Warp 分化)。
例如某个核函数内存在 if-else 语句,假设一个 Warp 内一半的线程执行了 if 分支,另一半线程执行了 else 分支,这样会出现 Warp 分化。调度不会违背 Warp 的基本原则,Warp 会选择串行执行这两个分支。例如首先让 16 个线程执行 if 分支,另外 16 个线程阻塞等待,执行完成后再交换。
Warp 分化会导致严重的性能下降。为了获得更好的性能,应当避免出现 Warp 分化。Warp 分化是一个 Warp 内的概念,只需要保证同一个 Warp 内的线程执行相同的指令即可。为了实现这一点,可以用 Warp ID 做区分,Warp ID 为奇数的线程执行 if 分支,Warp ID 为偶数的线程执行 else 分支。
分支效率(Branch Efficiency)是不会出现 Warp 分化的分支数占总分支数的比例。CUFA 编译器可以自动优化掉一些小的分支结构代码,避免出现 Warp 分化。
3.4、资源划分
一个 Warp 本地执行上下文通常包括程序计数器、若干寄存器、共享内存等。SM 中的每个 Warp 的上下文,在 Warp 的整个生命周期内,都存放在芯片上,Warp 与 Warp 之间的上下文切换是没有开销的。
每个 SM 能够分配的寄存器以及共享内存取决于具体的 GPU 架构。
如果一个 Block 已经被分配了资源,例如寄存器或者共享内存,就称这个块是一个活跃块(Active Block)。活跃块内的 Warp 就称为活跃 Warp(Active Warp)。
活跃 Warp 还可以进一步分为:
- Selected Warp:被调度器选中,正在执行的 Warp
- Eligible Warp:准备执行,但是还没有被选中的 Warp。有 32 个空闲 CUDA 核心,且该 Warp 要执行的指令的所有参数都已经准备好时,就说这个 Warp 是 Eligible Warp。
- Stalled Warp:由于某些原因(例如等待内存访问),被阻塞的、还未准备好执行的 Warp
SM 上的 Warp 调度器,每个时钟周期会选择一个 Active Warp,并分配到执行单元上执行。
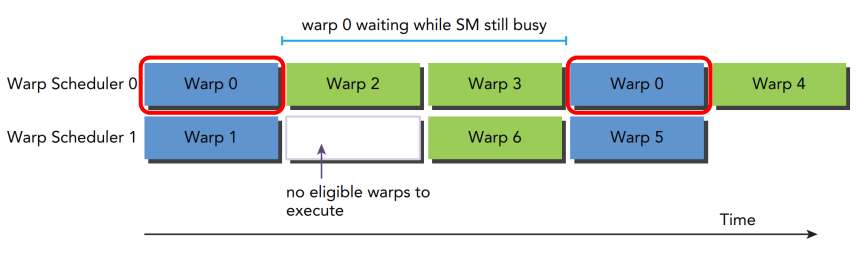
3.5、延迟隐藏
指令延迟(Instruction Latency)是指一个指令从发出到执行完成所需的实践。
一个 GPU 指令的延迟被其他 Warp 中指令的执行隐藏了。这里的隐藏是指,当一个 Warp 被阻塞时,其他 Warp 可以继续执行,这段“延迟”没有干等,也是在执行其他任务,就像没有一样,所以称为延迟隐藏(Latency Hiding):
算术运算指令的典型延迟是数十个时钟周期,而全局内存访问指令的典型延迟是数百个时钟周期。
这种隐藏能够成立的前提是,有足够多的其他的 Warp 可以被执行。Little’s Law给出了一个合理的估计:需要的 Warp 数量等于延迟(单位是时钟周期数)乘以吞吐量(单位是 Warp 数每周期)。
3.6、占用率
占用率(Occupancy)是指 SM 上活跃的 Warp 数量与 SM 上最大可活跃 Warp 数量的比率。可以使用cudaGetDeviceProperties()函数获取包括最大可活跃 Warp 数量在内的设备属性。
CUDA Toolkit 中包含了一个称为 CUDA Occupancy Calculator 的表格,给出了各种 Grid 和 Block 维度下的占用率,帮助开发者选择合适的 Grid 和 Block 维度。
一些可供参考的维度选择原则是:
- Block 的维度应该是 32 的倍数,这样每个 Block 可以分为多个完整的 Warp。这将极大提升访存效率。
- Block 的维度不应该太小,一个 Block 至少应该包括 128 个线程以上
- Block 的数量应当远远多于 GPU 的 SM 数量,以便充分并行化
- 根据核函数所需资源的多少调整 Block 的维度
- 通过实验来找到最优的 Grid 和 Block 维度
3.7、同步
CUDA 中的同步有两个级别:
- 系统级别:等待某个任务在 Host 上和 Divice 上都完成了
- 线程级别:等待某个 Block 内的所有线程都到达某个相同的点
前者可以使用cudaDeviceSynchronize()函数来实现,这个函数阻塞 Host 应用直到所有的 CUDA 操作完成。
对于后者,由于 Block 中的 Warp 的执行顺序和完成情况是不可预测的,CUDA 提供了 Block 内部的栅栏函数来实现。可以用__syncthreads()函数设置一个栅栏点,处于同一个 Block 内的所有线程会在这个点上等待,直到所有线程都到达这个点。
同一个 Block 内的线程可以通过寄存器或者共享内存共享数据,因此可能出现竞争条件。
不同的 Block 之间不允许通过寄存器或者共享内存共享数据。因此,GPU 可以以任意顺序调度 Block 的执行。
3.8、Grid 和 Block 维度的选择
选择 Grid 和 Block 的维度组合是一个重要的性能优化步骤。Grid 和 Block 的维度会影响到 GPU 的资源利用率、占用率和 Warp 的执行效率。
可以选取多种不同的组合运行,记录所需时间,然后选择最优的组合。
利用nvprof工具,还可以分析核函数的理论占用率。理论占用率(Achieved Occupancy)是一个核函数执行过程中,单个 SM 上活跃的 Warp 数与 SM 上最大可活跃 Warp 数的比率。理论占用率越高,表示核函数的资源利用率越高,但是不一定表示性能更优。具体可以用nvprof --metrics achieved_occupancy ./your_program来查看。
nvprof工具还可以分析内存操作。例如用nvprof --metrics gld_throughput ./your_program来查看全局内存访问吞吐量(Global Load Throughput)。同样,吞吐量越高也不一定表示性能更优。
3.9、避免 Warp 分化
考虑并行数组求和问题。可以将数组分为若干个小块,每一个线程负责处理求一个小块的和,最终需要将每个线程的结果汇总到一个全局数组中,也即进行归约。
之前介绍过树型结构的归约,也即相邻两个线程归约,然后再将结果归约到上一级,直到最后一个线程得到最终结果。显然在这个过程会出现 Warp 分化,不同线程需要根据自己的 ID 以及轮数来判断自己是否需要执行归约操作。
如果用 if 语句根据线程 ID 的奇偶性来判断是否执行归约操作,一个 Warp 内tid连续的线程会执行不同的指令,只有偶数序号线程执行分支,导致 Warp 分化:
1 | int tid = threadIdx.x; |
一种解决方法是重新安排每个线程要访问的元素,强迫连续的线程都执行分支,保证一个 Warp 内的所有线程都执行相同的指令,从而避免 Warp 分化:
1 | int tid = threadIdx.x; |
当然,也可以换用另一种树型归约,这种方法天然避免 Warp 分化:
1 | int tid = threadIdx.x; |
3.10、循环展开
循环展开(Loop Unrolling)可以减少分支跳转以及循环条件语句,其本质是将循环体中的代码复制多次,从而减少循环次数。循环展开因子也即循环体复制的次数。
还是上面那个规约的例子,假设到规约后期,需要规约的线程少于 32 个,则可以展开最后几轮的循环进行优化。当然,在知道循环次数的情况下,也可以直接展开整个循环。
CUDA 还支持 Device 上的模板函数,避免手动展开循环。
3.11、动态并行化
在之前的介绍中,CUDA 的核函数总是由 Host 的线程启动,GPU 的所有工作负载完全在 CPU 的控制下。CUDA 动态并行化(Dynamic Parallelism)允许由 GPU 来启动和同步新的核函数。
动态并行化中,核函数可以分为父核函数和子核函数,相应也有父 Grid/Block/Thread 和子 Grid/Block/Thread。子 Grid 必须在父 Grid/Block/Thread 完成之前完成。在所有子 Grid 完成之前,父 Grid/Block/Thread 不会被完成。
父 Grid 由 Host 线程启动、设置,子 Grid 由父 Grid 的线程启动、设置。父 Grid 会隐式地设置一个 Barrier,以等待所有子 Grid 完成。
4、CUDA 内存
基于时间局部性和空间局部性原理,设计出了层次化地内存系统:
层次化的内存能带来同时又较好的容量与延迟的访问体验。GPU 和 CPU 采用了相似的内存层次设计思想,与 CPU 相比,GPU 暴露了更多的内存层次,且提供了更多显式控制其行为的方式。
4.1、CUDA 内存模型
对于程序员而言,内存可以分为可编程的(Programmable)和不可编程的(Non-programmable)两种类型。CPU 上的 L1 缓存和 L2 缓存就是不可编程的。而在 CUDA 内存模型中,暴露了许多种类的可编程内存,例如寄存器、共享内存、本地内存、常量内存、纹理内存、全局内存等:
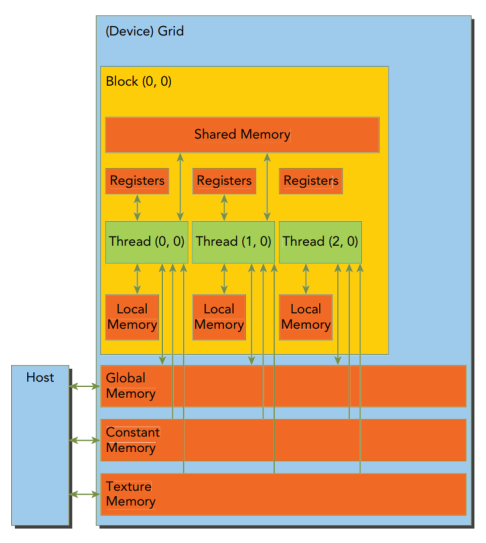
每个线程有自己的 Register 和 Local Memory,一个 Block 内的线程共享一块 Shared Memory,一个 Grid 内的所有线程都可以访问 Global Memory。一个 Grid 内的所有线程同时可以访问两块只读的内存:Constant Memory 和 Texture Memory。
Register 是 GPU 上最快的内存。任何一个在核函数内声明的自动变量(Automatic Variable,局部变量),不需要加上任何类型限定符,就会自动存储在 Register 中。
Register 中的变量的生命周期从核函数开始到核函数结束。
Register 的数量是有限的,是一种非常稀缺的资源,被一个 SM 上所有的活跃 Warp 瓜分。例如 Fermi 架构中,每个线程至多拥有 63 个 Registers。如果使用的 Register 数量超出限制,会转而存储在 Local Memory 中。
有资格放在寄存器中但是寄存器中放不下的变量,就会被放在 Local Memory 中,例如局部数组、局部结构体等。
虽然叫 Local Memory,但其实是全局内存的一部分,访问速度比寄存器慢得多(高延迟低带宽)。在较新的 GPU 架构中,Local Memory 中的数据也会在 SM 的 L1 缓存以及 Device 的 L2 缓存中缓存。
核函数中用__shared__修饰的变量会被放在Shared Memory中。Shared Memory 是片上内存,相比 Local Memory 和 Global Memory 有着低得多的延迟和高得多的带宽,其类似于 CPU 上的 L1 缓存,只不过是可编程的。
每一个 SM 的 Shared Memory 有限,被所有的 Block 瓜分。
Shared Memory 的生命周期从 Block 开始到 Block 结束。当一个 Block 执行完毕后,Shared Memory 中的数据会被释放。
由于 Shared Memory 被一个 Block 内的所有线程共享,所以是一种基本的线程间通信方法。
不同线程访问共享内存所需的时间可能不同,可以用void __syncthreads()函数来同步 Block 内的所有线程,确保所有线程都到达同一个点。
一般,一个 SM 的 L1 缓存和 Shared Memory 实际上共用 64KB 的片上内存,可以通过cudaFuncSetCacheConfig()函数来设置 L1 缓存和 Shared Memory 的划分比例。
用__constant__修饰的变量会被放在Constant Memory中。Constant Memory 存放在 Device 的内存中,并且缓存于专用的 Constant 缓存中。
常量必须声明为全局变量(在核函数外部),对所有线程可见且是只读的。Constant Memory 只能由 Host 用cudaMemcpyToSymbol()进行初始化。
同样,Constant Memory 也是有限的,一般为 64 KB。
Texture Memory 存储在 Device 内存中,并缓存于每个 SM 的只读缓存中。
Texture Memory 是一种通过专用只读缓存访问的 Global Memory,它针对二维数组的空间局部性访问进行了优化。一个 Warp 内的线程利用 Texture Memory 访问二维数据时,能够获得最佳性能。
Global Memory 是 GPU 上容量最大、延迟最高、使用最频繁的内存。在核函数中用__device__修饰的变量,或者 Host 代码中用cudaMalloc()分配的内存,都会被放在 Global Memory 中。
由于 Global Memory 被多个 Block 共享,不同 Block 的线程访问 Global Memory 就可能会出现竞争条件。跨 Block 的线程的执行,没有直接的同步机制。
Global Memory 可以以 32/64/128 字节为单位进行访问,每次访问就是一次事务。优化 Global Memory 的内存访问事务数量,可以显著提高性能。一个 Warp 每执行一次 load/store 操作,所需的内存访问事务数取决于要访问的地址的分布(如果是连续的,可以聚合成一个事务)以及内存地址的对齐方式(如果是对齐的,可以减少事务数)。
GPU 上的 Cache 和 CPU 上的 Cache 一样也是不可编程的,包括四种:
- L1 Cache:被所有 SM 共享,缓存 Local Memory 和 Global Memory 的数据
- L2 Cache:被所有 SM 共享,缓存 Local Memory 和 Global Memory 的数据
- Read-only Constant Cache:缓存 Constant Memory 的数据
- Read-only Texture Cache:缓存 Texture Memory 的数据
GPU 上只有 load 操作可以被缓存,store 操作不能被缓存(store 都是写直达)。
4.2、内存管理
内存分配和释放可以通过 CUDA Runtime API 的cudaMalloc()和cudaFree()函数来实现。初始化内存可以通过cudaMemset()函数来实现。
Device Memory 和 Host Memory 之间的数据传输可以通过cudaMemcpy()函数来实现。两者之间是通过 PCIe 总线连接的,速度相对较慢,通常会成为程序的性能瓶颈,应当尽量减少数据传输的次数。
默认情况下,Host 内存都是可分页内存(Pageable Memory),这样的内存可能转移到磁盘上,也可能被操作系统分配到另一片物理内存上。GPU 没有对 Host 操作系统的控制权,所以从可分页内存上进行数据传输是不安全的。
为了安全的从 Host 内存传输数据到 Device 内存:
- CUDA 会临时申请一片页锁定内存(Page-locked Memory)或者说固定内存(Pinned Memory),这种内存是不可分页的。
- 将可分页内存的数据复制到页锁定内存中
- 从页锁定内存传输数据到 Device 内存
可以用cudaMallocHost()函数来申请页锁定内存。页锁定内存可以直接被 Device 访问,且相较于可分页内存,页锁定内存的访问带宽高得多。
一般来说,Host 不能直接访问 Device 变量,反之亦然。一个特例是零拷贝内存(Zero-Copy Memory),Host 和 Device 都可以直接访问。利用零拷贝内存,可以避免 Host 和 Device 之间显式的内存传输。
零拷贝内存是一种特殊的固定内存,用cudaHostAlloc()函数来申请,用cudaFreeHost()来释放。cudaHostAlloc()的完整声明是cudaHostAlloc(void **pHost, size_t count, unsigned int flags),其中flags有四种:
cudaHostAllocDefault:默认的页锁定内存,行为与cudaMallocHost()相同cudaHostAllocPortable:可被多个 CUDA 设备共享的页锁定内存cudaHostAllocWritableCombined:适用于被 Host 写、Device 读的页锁定内存cudaHostAllocMapped:申请一片被映射到 Device 地址空间的 Host 内存,就是我们说的零拷贝内存
申请之后,可以用cudaHostGetDevicePointer()函数获取零拷贝内存的 Device 指针。Host 代码可以直接用这个指针访问零拷贝内存中的数据。
零拷贝内存的访问速度很慢,每一个对于映射的内存的事务都需要通过 PCIe 总线进行。对于 Host 和 Device 之间共享少量数据的场景,零拷贝内存是一个不错的选择。但是对于大量数据,零拷贝内存的性能会很差。
较新的设备支持一种特殊的地址模式——统一虚拟地址(Unified Virtual Addressing,UVA),将 Host 和 Device 的编码到同一片地址空间中:
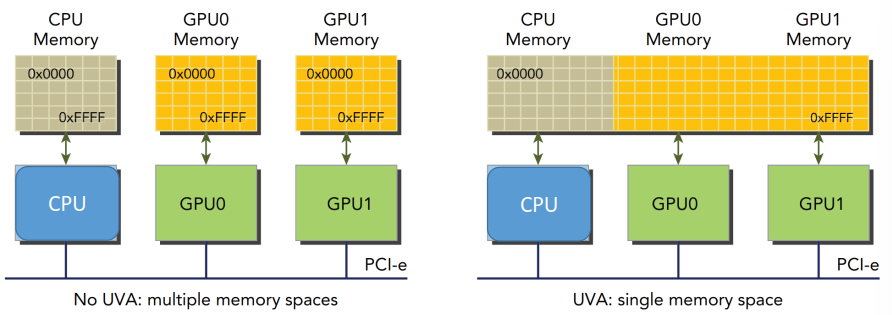
统一之后,例如在使用零拷贝内存时,就不用再使用cudaHostGetDevicePointer()函数获取 Device 指针了。
另一种特殊的地址模式是统一内存(Unified Memory,UM)。统一内存是一片托管内存,Host 和 Device 可以用相同的地址去访问。底层会自动在 Host 和 Device 之间传输统一内存里的数据。
托管内存(Managed Memory)是由系统管理的内存,用__managed__修饰的变量会被放在托管内存中,或者可以用cudaMallocManaged()函数来申请托管内存。非托管内存需要应用显式地创建和复制。
4.3、内存访问
最大化全局内存带宽的利用率也是性能优化的关键。根据 Warp 内要访问的内存地址的分布,内存访问可以分为不同的模式。
4.3.1、对齐/合并访问
众所周知,全局内存有缓存机制。
如果要访问的第一个地址恰好就是某个缓存行的开始,那么就称这个访问是对齐访问(Aligned Access)。由于缓存行是整个读出来的,如果没有对齐,就相当于读一些不需要的数据,造成带宽的浪费。
如果一个 Warp 要访问的地址恰好是连续的,则可以合并起来一次性访问,这称为合并访问(Coalesced Access)。合并访问可以极大地提高内存访问的效率。